

When we talk about customer data and how it’s obtained (at least in the context of the internet industry), one usually thinks about tracking users and recording their behavior on websites and platforms. However, based on the intentionality of the signal provided by the customer, there are two types of data that recommender systems and other personalization tools can leverage. Recording user behavior (where they click, what pages they watch, what search terms they use, etc.) presents us with „implicit feedback”.
When we talk about customer data and how it’s obtained (at least in the context of the internet industry), one usually thinks about tracking users and recording their behavior on websites and platforms. However, based on the intentionality of the signal provided by the customer, there are two types of data that recommender systems and other personalization tools can leverage. Recording user behavior (where they click, what pages they watch, what search terms they use, etc.) presents us with „implicit feedback”. Implicit user feedback generally refers to data traits a customer leaves behind when naturally interacting with a site or platform.
There is another type of data, which can be considerably harder to obtain and analyze, but in certain cases, it can be much more valuable than „simple” clickstream data. Such data is called „explicit user feedback”, a category that comprises information about a user and his preferences that he expresses explicitly. This type of feedback can be collected in a million ways, for example through customer surveys, review boxes or input fields attached to registration or signup forms. In this article, I will briefly outline some technologies, practices, and ongoing research that aim to employ explicit feedback in creating enhanced personalized online experiences for users.
User ratings – the most common type of explicit user feedback

User ratings are arguably the most widely used and most easily quantifiable and analyzable type of explicit feedback. Even though such ratings represent insufficient information value to provide a basis for in-depth preference profiling, they can, for example, complement recommender algorithms that rely on a breadth of different data points. Amazon’s famous recommender system, originally patented in 1999, is also known to incorporate user ratings into its recommendation generation process.

Aggregated rating data is also a very good indicator of general sentiment and even more importantly, online ratings seem to represent information that users trust and consider when making purchase decisions. For instance, in a 2011 study, Harvard Business School Assistant Professor Michael Luca found, that a one out of five star increase in a restaurant’s average rating on Yelp results in a 5-9 percent increase in its revenues.
User reviews
The growing popularity of social media and eCommerce sites has encouraged users to habitually write reviews describing their experiences regarding products they’ve bought, services they’ve used, movies they’ve watched, and so on. Such data is available abundantly and represent enormous value for user profiling and personalization technologies. A paper published last year, titled “Recommender systems based on user reviews: the state of the art” seeks to summarize ongoing research that aims to extract information from user reviews and use it to build fine-grained preference models and capture the multi-faceted nature of user opinions. The authors of the paper argue that incorporating this kind of information into the recommendation process can help tackle a number of persistent recommendation problems, such as rating sparsity and the cold start.
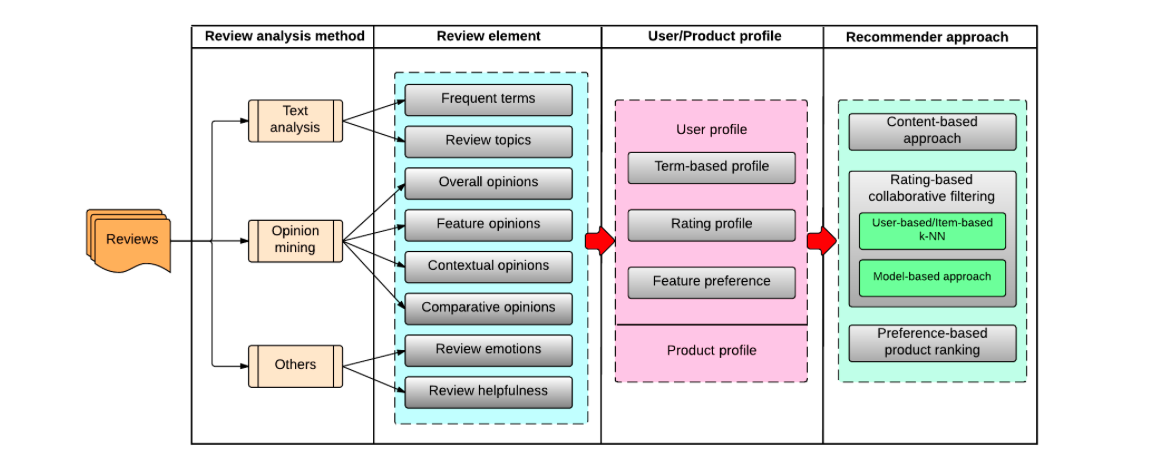
They introduce an array of research areas that aim to employ reviews in the process of creating and refining user profiles. The presented approaches include profiling based on the terms used in reviews, weighing ratings based on the associated review’s total helpfulness score, devising ratings from reviews, and using the textual information to derive specific feature preferences.
As is the case with ratings, users tend to look at reviews as a trustworthy and relevant information source when making purchase decisions online. According to a survey by BrightLocal, 88% of users trust online reviews as much as personal recommendations. The same survey found that only 12 percent of the population did not regularly read reviews for consumer products.
Soliciting explicit feedback from customers
While implicit feedback is generated whenever a user interacts with a website or platform, explicit feedback is harder to obtain, as it requires proactivity on the user’s part. Many companies understand this very well and apply different methods to incentivize their customers to take the time and provide them with such information. One popular way to achieve this is through a badge-based gamification system, where users get badges or certain privileges for giving their feedback to the community. Sites like TripAdvisor or the popular Stack Exchange platforms use this method with great results.
Another interesting approach is what researchers working on the EU-funded CrowdRec project suggested in a paper titled „Activating the Crowd: Exploiting User-Item Reciprocity for Recommendation”. The authors of the paper envision a recommender system that leverages explicit feedback in such a way that it provides a direct answer to the „data sparsity problem”. In practice, this means that the system asks users for feedback specifically about products that it cannot recommend with enough confidence due to the lack of interactional data (implicit feedback).
The paper outlines a number of prerequisites for such a system to function properly. Firstly, it needs to present users with ample incentive to provide feedback. Secondly, users must have some knowledge of the product or service, so their contribution will indeed be valuable. In one of my earlier articles, I argued that B2B eCommerce could be an ideal domain to implement such a solution as B2B purchases are more conscious and instrumental by nature and buyer-seller relations in this field typically last longer and are based on loyalty. Therefore, business buyers are incentivized to enrich their profiles through explicit feedback in order to be provided a more personalized and more convenient experience. Moreover, they’re also generally more knowledgeable about the types of products they’re purchasing, so their reviews and ratings will indeed serve as valuable sources of information.
Incentivization is, of course, above all a creative task. Take Craft Coffee, a subscription-based coffee delivery service, for an instance. Their solution called the Coffee DNA Project is based on an analysis of thousands of coffees, all from independent roasters. By analytic means, they were able to identify certain traits and flavor profiles that were consistent among them. How is this related to explicit feedback? Well, when someone signs up for a subscription on their site, all they’re asked is what coffee they currently drink. The company’s recommendation algorithm then tries to find an artisan brand that has a similar taste quality and price point. Through the promise of finding a coffee they’ll love, Craft Coffee incentivizes customers to provide them with information on their coffee preferences. Later on, as a user rates several brands and coffees, the system refines and extends their profiles to make even more accurate recommendations.
As I tried to illustrate, classic types of explicit feedback, such as ratings and reviews are trusted sources of information for customers making purchases online. However, as recommender systems and personalization technologies get better and better at incorporating explicit feedback into their models, further layers of utility will be added to such data. It’ll be interesting to see what new, creative ways will be introduced to collect explicit user feedback, in the light of such changes.







{kind=link}