

Critical infrastructure (CI) is a term used by large businesses (and other organizations, like government agencies) that refers to the most important components within a given software architecture. Importance is usually defined by the needs of stakeholders – often this is a business’ customers. But it might also be finance or marketing departments who need to understand revenue or user behavior.
This is an extract from Artificial Intelligence for Big Data by Anand Deshpande and Manish Kumar.
As you can imagine a digitized infrastructure produces a wealth of data. That’s great because this data can produce high quality insights that can aid decision making – but a digitized infrastructure can also be vulnerable to cyberattacks too. For example, Stuxnet, a malicious worm which was discovered back in 2010, targeted SCADA (Supervisory Control and Data Acquisition) systems and caused significant damage to fuel enrichment plans in Iran by interfacing with Programmable Logic Controllers (PLCs).
Fortunately, the wealth of data that modern digitized infrastructures provide can also be used to defend against cyberattacks. By using a combination of data from components within the infrastructure as well as data from outside of it, it’s possible to build a pretty robust defense mechanism.
Essentially, you need 4 things – ‘4 Vs’ – which together ensure that you can use big data to guard against cyberattacks:
● High volume of data
● A variety of data
● Data at velocity (speed at processing and its availability)]
● Valuable data – high quality data that is relevant
Those are the core components, but the process is important. We’ll look at that now.
Cybersecurity and big data: the process
A data-driven framework for cybersecurity has 3 elements, as the diagram below shows:
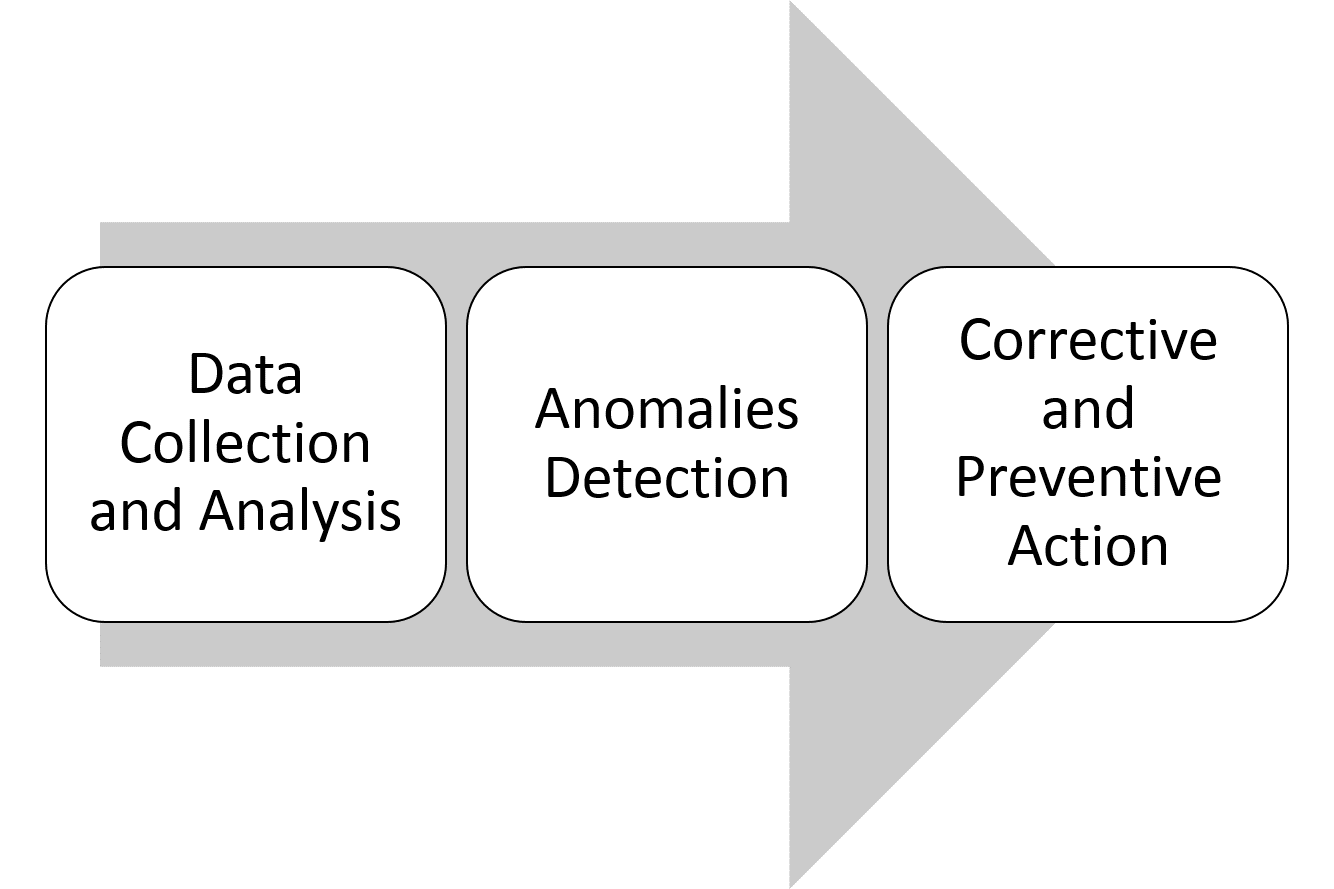
Let’s go through each of these steps.
Data collection and analysis
The systems that constitute critical generate data assets in the form of event logs. The data collection stage is where you gather these logs from all the components, both software and hardware.
As well as those components within your infrastructure, you also need contextual information. You can only get this by collecting data from outside of your immediate infrastructure. For example, historical data is useful here as it allows you to generate insights based on past events. Using supervised learning techniques, for example, you can take similar steps based on what is optimal according to past data.
The data – or ‘log’ – that is generated by these various components can be categorized in a number of different ways:
Structured data: In the case of structured format, the individual elements (or attributes) of an entity are represented in a predefined and consistent manner across time periods. For example, the logs generated by the web servers (HTTP log) represent fields such as the IP address, the time the server finished processing the request, the HTTP method, status code, and so on. All these attributes of a web request are represented consistently across requests. The structured data is relatively easy to process and does not require complex parsing and pre-processing before it is available for analysis. With structured data, processing is fast and efficient.
Unstructured data: This is a free-flowing application log format that does not follow any predefined structural rules. These logs are typically generated by the applications and are meant to be consumed by someone who is troubleshooting the issues. The intention is to log the events without an explicit goal of making the logs machine readable. These logs require extensive preprocessing, parsing, and some form of natural language processing before those are available for analysis.
Semi-structured data: This is a combination of structured and unstructured data where some of the attributes within structured format are represented in an unstructured manner. The information is organized into fields which can be easily parsed but the individual fields need additional preprocessing before being used in analysis.
Anomaly detection
As you start gathering data, patterns begin to form within that data. This pattern generally remains consistent, but there could be some fluctuations. For example, an online retailer might expect more orders during the holiday season.
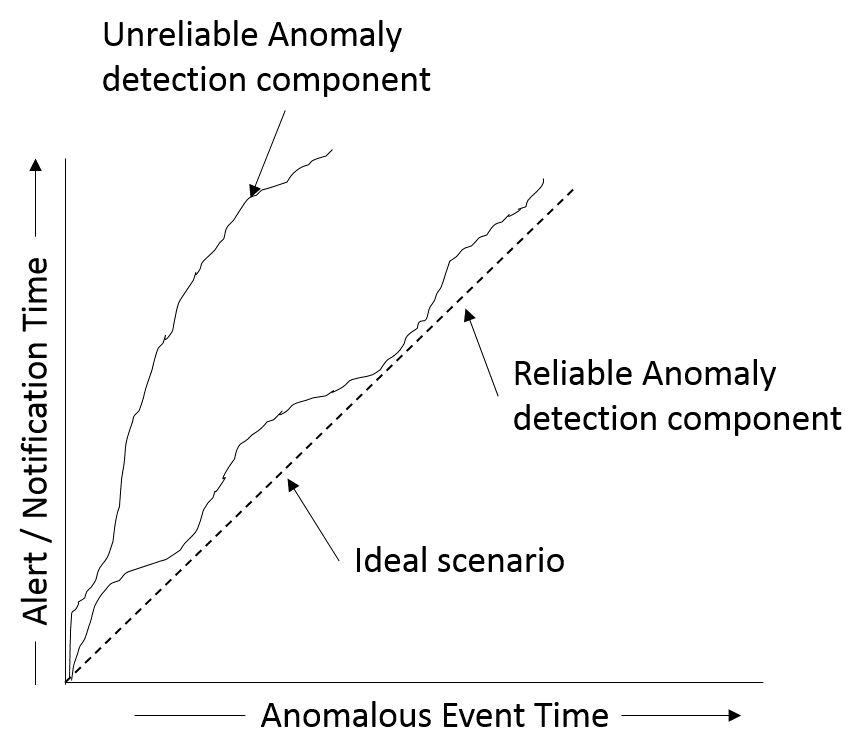
However, when there is an unanticipated change in the regular pattern of data anomaly detection will trigger an alert and notification. One of the most important characteristics of reliable and accurate anomaly detection is that it should be able to generate the alert as soon as the event occurs, with minimum lag between event time and the alert/notification time.
The diagram below illustrates the ideal, reliable, and unreliable anomaly detection components based on the time difference between the event and alert time:
Corrective and preventive actions
When suspicious activity is detected, there are two ways to respond. In the first case, the alert/notification requires manual intervention in order to trigger the corrective action. In the second case, the system itself takes some corrective action based on the context and the acceptable threshold of the error margin.
For example, if an attack into thermostat circuitry starts increasing the temperature of the cold storage in an unanticipated manner, the system can switch the control to an alternate thermostat and ensure that the temperature is back to normal and maintained at normal levels. This component can use supervised learning as well as reinforcement learning algorithms for triggering the corrective actions on their own based on historical data or the reward function. When the correction is applied and the infrastructure’s state is restored to normal, the system will need to analyze the root cause and train itself to take preventive actions.
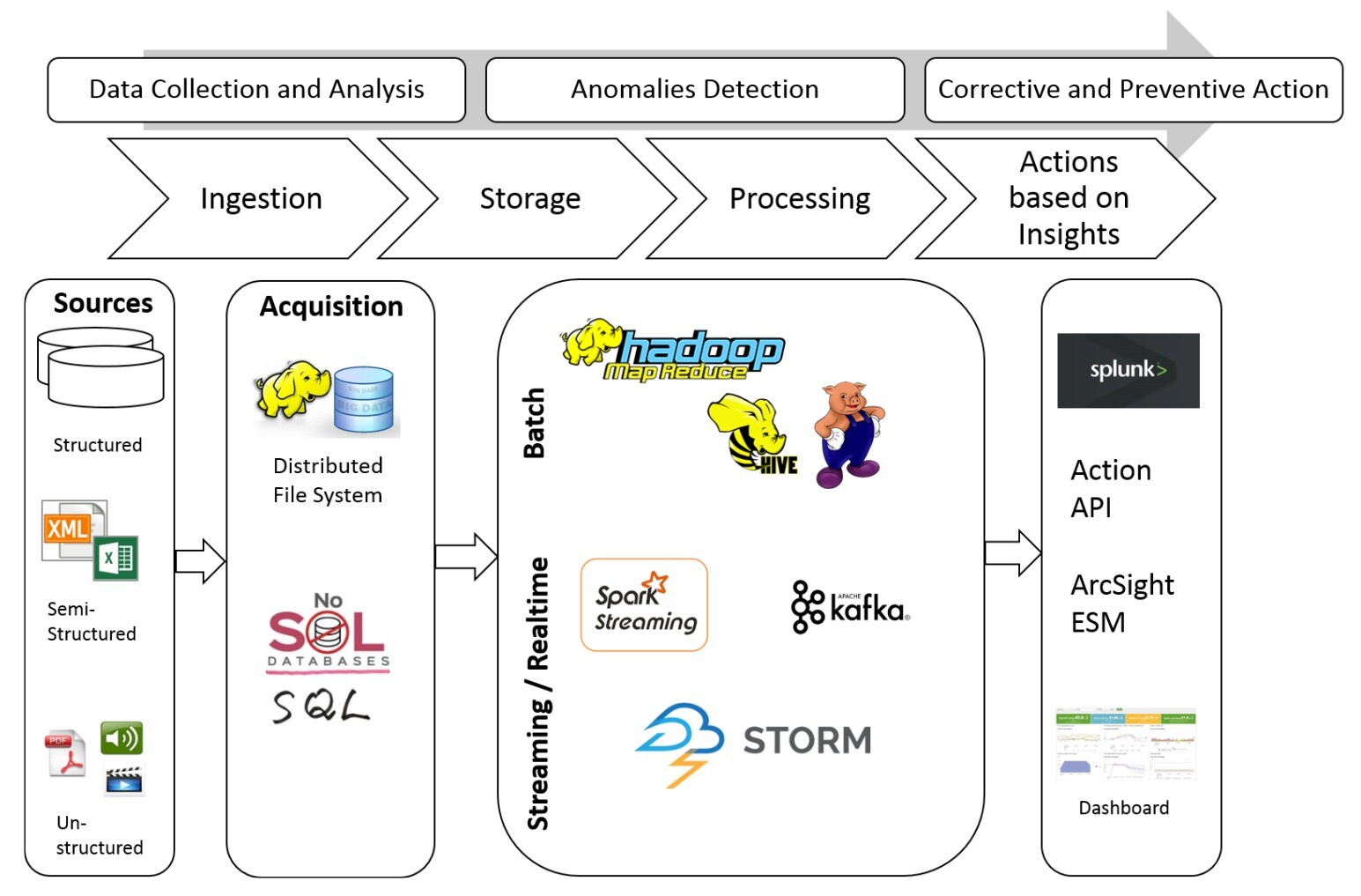
Mapping the model on to a big data infrastructure
In typical Big Data environments you will find a layered architecture. Layers within the data processing pipeline help in decoupling various stages through which the data passes to protect the infrastructure.
How the data ‘flows’ through our schema can be seen in the diagram below. Where different frameworks fit into this process are also shown:
Clearly, big data is going to play a big part in cybersecurity in the future. As threats grow, using the data at our disposal to recognise those threats quickly is going to be vital.
If you want to learn more about the relationship between big data, artificial intelligence, and cybersecurity, check out Artificial Intelligence for Big Data From Packt.
Get the eBook for just $10 (limited period offer).






{kind=link}