

Data lakes and data warehouses are probably the two most widely used structures for storing data. In this article, we will explore both, unfold their key differences and discuss their usage in the context of an organization.
Data Warehouses and Data Lakes in a Nutshell
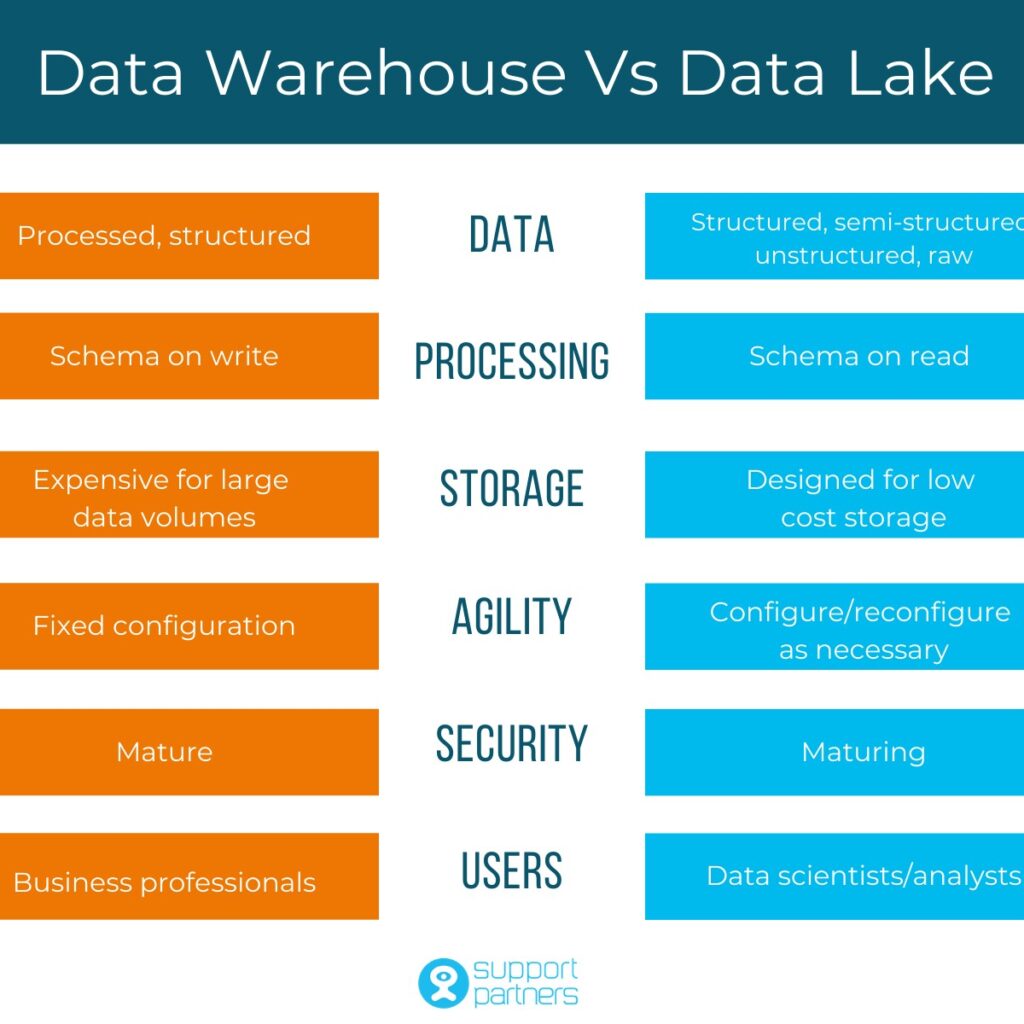
A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Such stores are vital to companies as they can be used to deliver insights from across the organization to support decision making.
On the other hand, data lakes are flexible storages used to store unstructured, semi-structured, or structured raw data. The stored data is unprocessed, and the structure is usually applied when it is retrieved. Note, however, that a data lake is not a replacement for a data warehouse.
Key Differences
It is essential to consider all related factors before choosing how to house the data in an organization and whether you need to store data coming from a particular source into a data lake or a data warehouse. Typically, these considerations come down to the four topics discussed below.

Data Type and Processing
As we already discussed, data lakes can be used to store any form of data, be it unstructured or semi-structured. In comparison, data warehouses are only capable of storing structured data.
Since data warehouses can deal only with structured data, they also require extract, transform, and load (ETL) processes to transform the raw data into a target structure (Schema on Write) before storing it in the warehouse. In other words, data warehouses store historical data that has been pre-processed to fit a relational schema.
Data lakes are much more flexible as they can store raw data, including metadata, and schemas need to be applied only when extracting data. This is essentially the most fundamental difference between a data warehouse and a data lake.
Target User Group
Different users may require access to different storage types. Usually, business or data analysts need to extract insights for reporting purposes, so data warehouses are more suitable for them.
On the other hand, a data scientist may require access to unstructured data to detect patterns or build a deep learning model, which means that a data lake is a perfect fit for them.
Ecosystem
Another important factor to consider when choosing between data warehouses or lakes is your organization’s existing technology ecosystem. Data lakes have become quite popular due to the emerging use of Hadoop, which is an open-source software.
If your organization does not favor open-source software, then moving data into data lakes could be challenging.
Budget
The data management plan always needs to take into account the cost of the technologies and architectures one intends to use or build. Data lakes are far less costly than data warehouses as the data is stored in its unprocessed raw format in lakes, taking up less storage space.
Which to Choose?
Both data warehouses and lakes are used by organizations as centralized data stores that enable different users and organization units to access and use data to extract insights and perform any analysis. Usually, an organization will need both a data lake and a warehouse to support all the required use-cases and end users.
A data lake is capable of housing all kinds of data in any form, structured to unstructured. Additionally, it does not require any preprocessing before storing the data, as this can happen once it is stored in the data lake. Data lakes are mostly useful to data scientists and engineers that require access to unstructured data to build artificial intelligence or machine learning models. Data lakes are also more cost efficient than data warehouses as they don’t require stored data to have any particular format, such as a schema.
Inversely, a data warehouse is only capable of storing structured data that is ready to be analyzed by specific organization units to unveil business insights. Therefore, ETL processes are usually required to be built around the data warehouse. ETL functionality enables data to be stored in the expected format and extracted or transformed so that users can perform particular tasks over them. For that reason, data warehouses are best suited for business or operations analysts who require access to relational data with a schema that will enable them to create reports and support decision making by discovering insights.
A Final Word
In this article, we discussed the key differences between data lakes and warehouses. Note, though, that this is not an apple-to-apple comparison. Both support different use cases and serve different users, and organizations usually require both to operate efficiently.
Data lakes are more flexible and schema-less stores capable of storing unstructured, semi-structured, or structured data. They are usually useful to more technical users such as data scientists or engineers. On the other hand, data warehouses can only accept relation data, which is more useful to less technical people who need access to ready-for-analysis data.







{kind=link}