


 Okay, this is where the rubber meets the road. I have three minutes (or ~450 words) to respond to Anne’s final statement and summarize why I still believe a data lake is essential for any organization to take full advantage of its data. Let’s get started!
Okay, this is where the rubber meets the road. I have three minutes (or ~450 words) to respond to Anne’s final statement and summarize why I still believe a data lake is essential for any organization to take full advantage of its data. Let’s get started!
Timer: START!
More Read

Where We Stand
I put together this simple data graphic to help summarize the core arguments brought up during this debate. It focuses on data variety and purpose:
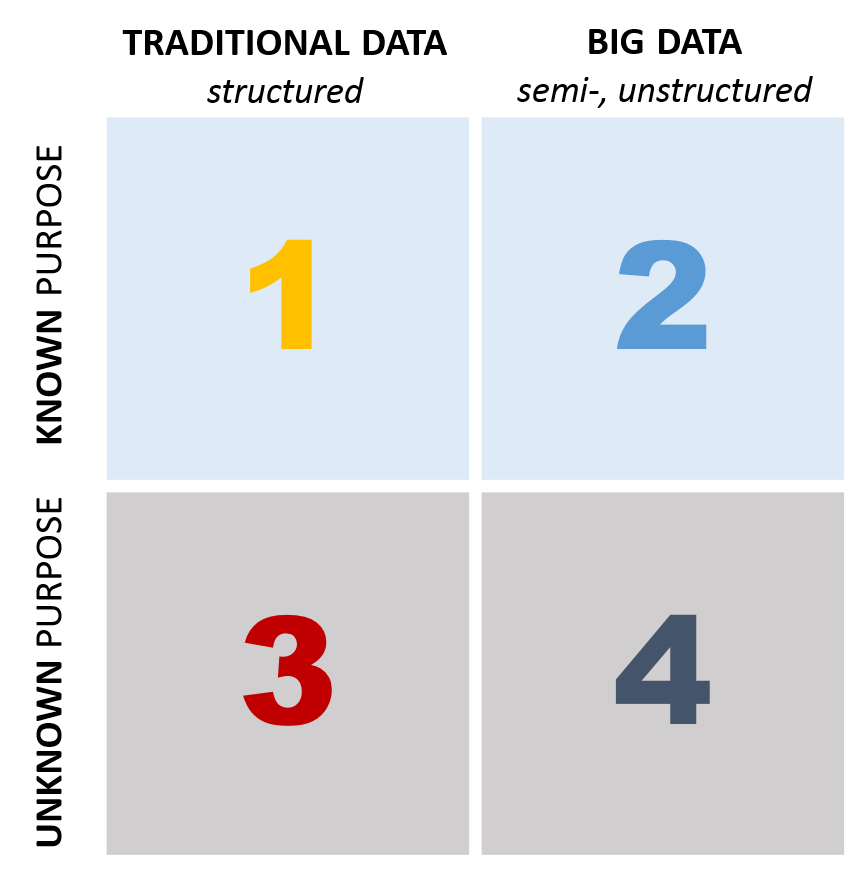
And here’s our positions for each quadrant:

My Final Rebuttal
Whereby Anne is focused on data in quadrants 1 and 2, my focus is on all four quadrants – and a centralized storage repository, like a data lake, is the first step in bringing all this data together in its raw, native format – without the limitations and biases of existing, relational systems.
Where data is stored is important. None of the data in these four quadrants is new. We’ve had access to all this digital data for several decades—in databases, data warehouses, file systems, applications, etc. What is new, however, is that we now have the technologies—the most popular right now being Hadoop—to bring the data from any quadrant all together, process it any way we want, and then store the processed results anywhere we want. And if we don’t like the results, or we have new data, or we have different questions, it’s no big deal to go back to the original, raw data and start over. You cannot do this in Anne’s world.
Different skills? That’s good! Anne also talks about the skills required for the data lake. Yes, these big data technologies are new, they’re evolving, and there’s a lot of experimentation going on to figure out what’s needed, what’s not, what should stick, what shouldn’t, etc. Thus, it should be no surprise that as our technologies evolve, so will the skills required. So a lack of skills for these newer technologies should not be seen as a negative. It’s an opportunity to take what we have and know to a new level and help prepare the next generation to excel in our data-saturated society.
My Final Summary
What a data lake is not. A data lake is not a panacea or a geographic cure or another version of the data warehouse…or even a data swamp. If an organization is already bad at governing and managing its existing data, then adding a data lake will only make matters worse. I will be the first to say: Don’t go there.
What a data lake is. It’s a newer storage alternative for organizations that want to mix-and-match their data (from quadrants 1-4 above) so that they can analyze it and discover insights that they would never be able to find with existing, relational technologies.
An organization will be able to take full advantage of its data if there’s a way for them to bring it all together without breaking the bank. The data lake provides that opportunity.
Timer: STOP! Word count: 575 (oops!)
A note to Anne: While the boss is putting together her summation of this debate, want to meet up at the bar for a drink or three? I’m buying.
Previously in the Data Lake Debate:
- The Introduction – by Jill Dyche
- Pro’s Up First – by Tamara Dull
- Questioning the Pro – by Anne Buff and Tamara Dull
- Negative Puts a Stake in the Ground – by Anne Buff
- Pro Cross-Examines Con – by Tamara Dull and Anne Buff
- Pro Delivers First Rebuttal – by Tamara Dull
- The Final Word from Negative – by Anne Buff






{kind=link}