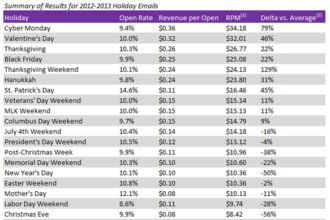
The debate over the accuracy – and quality – of survey research conducted online is flaring at the moment, at least partly in response to a paper by Yeager, Krosnick, Chang, Javitz. Levendusky, Simpson and Wang: “Comparing the accuracy of RDD telephone surveys and Internet surveys conducted with probability and non-probability samples.” Gary Langer, director of polling at ABC News, wrote about the paper in his blog “The Numbers” on September 1. In a nutshell, the paper compares survey results obtained via random-digit dialing (RDD) with those from an Internet panel where panelists were recruited originally by means of RDD and from a number of “opt-in” Internet panels where panelists were “sourced” in a variety of ways. The results produced by the probability sampling methods are, according to the authors, more accurate than those obtained from the non-probability Internet samples. You can find a response from Doug Rivers, CEO of YouGov/Polimetrix (and Professor of Political Science at Stanford) at “The Numbers,” as well as some other comments.
The analysis presented in the paper is based on surveys conducted in 2004/5. In recent years the coverage of the RDD sampling frame has .. …
The debate over the accuracy – and quality – of survey research conducted online is flaring at the moment, at least partly in response to a paper by Yeager, Krosnick, Chang, Javitz. Levendusky, Simpson and Wang: “Comparing the accuracy of RDD telephone surveys and Internet surveys conducted with probability and non-probability samples.” Gary Langer, director of polling at ABC News, wrote about the paper in his blog “The Numbers” on September 1. In a nutshell, the paper compares survey results obtained via random-digit dialing (RDD) with those from an Internet panel where panelists were recruited originally by means of RDD and from a number of “opt-in” Internet panels where panelists were “sourced” in a variety of ways. The results produced by the probability sampling methods are, according to the authors, more accurate than those obtained from the non-probability Internet samples. You can find a response from Doug Rivers, CEO of YouGov/Polimetrix (and Professor of Political Science at Stanford) at “The Numbers,” as well as some other comments.
The analysis presented in the paper is based on surveys conducted in 2004/5. In recent years the coverage of the RDD sampling frame has deteriorated as the number of cellphone-only users has increased (to 20% currently). In response to concerns of several major advertisers about the quality of online panel data, the Advertising Research Foundation (ARF) established an Online Research Quality Council and just this past year conducted new research comparing online panels with RDD telephone samples. Joel Rubinson, Chief Research Office of The ARF, has summarized some of the key findings in a blog post. According to Rubinson, this study reveals no clear pattern of greater accuracy for the RDD sample. There are, of course, differences in the two studies, both in purpose and method, but it seems that we can no longer assume that RDD samples represent the best benchmark against which to compare all other samples. Comparing the “accuracy” of different sampling methods is no easy task. There are multiple sources of “survey error” including measurement error and non-response in addition to pure sampling error. The benchmark measures may have errors as well. For example, some of the accuracy measures reported by Yeager et. al. are based on comparison to rigorously conducted probability sample surveys with high (e.g., 80%) response rates. Non-survey criteria, such as the incidence of passport ownership, also provide measures of accuracy. Still, even non-survey measures may be approximations. Yeager et al estimated a population incidence by dividing the number of passports in existence by the size of the population, but they point out a discrepancy between the age range for the actual number of passports and the data from their survey. While this probably does not have a material effect on their conclusions, it does illustrate the difficulty of finding or developing accuracy criteria.
Another problem in making judgments about method accuracy lies in the relatively small sample of observations. For example, the Yeager et al study compares a single RDD sample with several non-probability samples from different online panel providers. While they identify and add in some additional RDD samples for part of the analysis, we are still looking at only a handful of samples. Similarly, the ARF Foundations of Quality study compares a limited number of samples (and only one sample from each online panel provider). Probability sampling is the gold standard because we have a theoretically specified sampling error. In practice, however, we almost never have true “probability” samples. In the case of RDD samples, each telephone number has some known probability of being sampled, but the probability of any individual being included in the final data is unknown, given contact failures, varying household size, refusal to participate when contacted, and so forth. It’s convenient to assume that differences in the probability of reaching a given individual are randomly distributed across the sampling frame, but that’s not always the case. Selection bias may be as problematic for telephone surveys as it is for opt-in online surveys.
One of the arguments for developing online panels in the first place was based on the belief that if the panel provided coverage of the population of interest–meaning that the sample encompassed the range of variability in the population if not the distribution, you could use post-stratification or “weighting” to approximate the population distribution. Both Yeager et al and my reading of the ARF study results posted by Rubinson suggest that post-stratification may not achieve the desired results.
I think it’s safe to say that online research with non-probability samples is here to stay. For one thing, the cost advantage can be considerable, especially when trying to reach a small, specialized target group. For a pharmaceutical company, for example, the ability to conduct surveys among a non-probability panel of individuals with a particular chronic illness at a fraction of the cost of RDD sampling may well outweigh the advantages of probability sampling. That being the case, is there any way to increase our confidence in the results we get from these non-probability samples?
Much of the effort to date in quality improvement for online interviewing has focused on respondent quality – verifying identity and blocking fraudulent respondents from participating in surveys. While this is important, I think that the online sample providers have an opportunity to develop a better understanding of the variability that occurs in online sampling. This would require consistent and ongoing analysis of all samples generated (including the final sample of respondents for any project). This probably will require some “standard” measures for demographics and maybe some key non-demographic variables for each panel member. Ideally, this will lead to better understanding of the differences between non-probability opt-in panels and probability samples. New sampling strategies may be effective. For one example, check out this white paper on representative sampling in Internet panels by Doug Rivers. And we should remind ourselves that random sampling error is only one way to construct “confidence” intervals. We can look at convergent sources of information and perhaps apply some Bayesian thinking to our judgment processes.
It’s possible that broader technological changes – perhaps a mass migration to “gmail” from Google – will lead to a more comprehensive sampling frame for online panels – so that something resembling a probability sample can be constructed using email recruitment rather than RDD sampling.
Copyright 2009 by David G. Bakken. All rights reserved.





![]()