
At its Teradata Partners conference in Dallas, a broader vision for big data and analytics was articulated clearly. Their pitch centered on three areas – data warehousing, big data analytics and integrated marketing – that to some degree reflect Teradata’s core market and acquisitions in the last few years of companies like Aprimo who provides integrated marketing technology and Aster in big data analytics. The keynote showcased the company’s leadership position in the increasingly complex world of open source database software, cloud computing and business analytics.
At its Teradata Partners conference in Dallas, a broader vision for big data and analytics was articulated clearly. Their pitch centered on three areas – data warehousing, big data analytics and integrated marketing – that to some degree reflect Teradata’s core market and acquisitions in the last few years of companies like Aprimo who provides integrated marketing technology and Aster in big data analytics. The keynote showcased the company’s leadership position in the increasingly complex world of open source database software, cloud computing and business analytics.
As I discussed in writing about the 2013 Hadoop Summit, Teradata has embraced technologies such as Hadoop that can be seen as 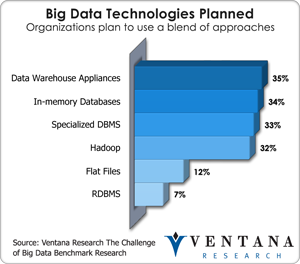 both a threat and an opportunity to its status as a dominant database provider over the past 20 years. Its holistic architectural approach appropriately named Unified Data Architecture (UDA) reflects an enlightened vision, but relies on the ideas that separate database workloads will drive a unified logical architecture and that companies will continue to rely on today’s major database vendors to provide leadership for the new integrated approach. Our big data benchmark research finds support for this overall position since most big data strategies still rely on a blend of approaches including data warehouse appliances (35%), in-memory databases (34%), specialized databases (33%) and Hadoop (32%).
both a threat and an opportunity to its status as a dominant database provider over the past 20 years. Its holistic architectural approach appropriately named Unified Data Architecture (UDA) reflects an enlightened vision, but relies on the ideas that separate database workloads will drive a unified logical architecture and that companies will continue to rely on today’s major database vendors to provide leadership for the new integrated approach. Our big data benchmark research finds support for this overall position since most big data strategies still rely on a blend of approaches including data warehouse appliances (35%), in-memory databases (34%), specialized databases (33%) and Hadoop (32%).
Teradata is one of the few companies that has the capability to produce a truly integrated platform, and we see evidence of this by its advances in UDA, the Seamless Network Analytics Processing (SNAP) Framework and the Teradata Aster 6 Discovery platform. I want to note that the premise behind UDA is that the complexities of the different big data approaches is abstracted from the user which may access the data through tools such as Aster or other BI or visualization tool. This is important because it means that organizations and their users do not need to understand the complexities of the various types of emerging database approaches prior using them for competitive advantage.
The developments in Aster 6 show the power of the platform to access new and different workloads for new analytic solutions. Teradata announced three key developments about the Aster platform just before the Partners conference. A graph engine is added to complement the existing SQL and MapReduce engines. Graph analytics has not had as much exposure as other NoSQL technologies such as Hadoop or document databases, but it is beginning to gain traction for specific use cases where relationships are difficult to analyze with traditional analytics. For instance, any relationship network, including those in social media, telecommunications or healthcare, can use graph engines, but they also are being applied for basket analysis in retail or behind the scenes in areas such as master data management. The reason that the graph approach can be considered better in these situations is that it is more efficient. For example, it is easier to look at a graph of a social network and understand existing relationships and what is occurring, than trying to understand this same type of data looking at rows and columns. Similarly, using the ideas of nodes and edges, a graph database helps discover very complex patterns in the data that may not be obvious otherwise.
An integrated storage architecture compatible with Apache Hadoop HDFS, its file system, is another important development in Aster 6. It accommodates fast ingestion and preprocessing of multi-structured data. Perhaps the most important development for Aster 6 is the SNAP Framework, which integrates and optimizes execution of SQL queries across the different analytic engines. That is, Teradata has provided a layer of abstraction that removes the need for expertise in different flavors of NoSQL and puts it into SQL, a language that many data-oriented professionals understand.
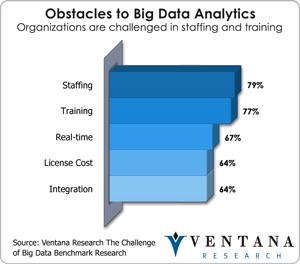 Our big data benchmark research shows that staffing and training are major challenges to big data analytics for three-fourths of organizations today and advances in Aster 6 address multiple analytical access points needed in today’s big data environment. These three analytic access points which are the focus for Teradata are the data scientist, the analyst and the knowledge worker, as described in my recent post on the analytic personas that matter. For the first group of data scientists, there are open APIs and an integrated development environment (IDE) in which they can develop services directly against the unified data architecture. Analysts, who typically are less familiar with procedural programming approaches, can use the declarative paradigm of SQL to access data and call up functions within the unified data architecture. Some advanced algorithms are included now within Aster, as are a few big data visualizations such as sankey; on that topic, I think the best interactive sankey visualization for Aster is from Qlik Technologies, and was showcased at the company’s booth at the Teradata conference. The third persona and access point is the role of the knowledge worker, who accesses big data through BI and visualization tools. Ultimately, the Aster 6 platform brings an impressively integrated access approach to big data analytics; we have not yet seen its equal elsewhere in the market.
Our big data benchmark research shows that staffing and training are major challenges to big data analytics for three-fourths of organizations today and advances in Aster 6 address multiple analytical access points needed in today’s big data environment. These three analytic access points which are the focus for Teradata are the data scientist, the analyst and the knowledge worker, as described in my recent post on the analytic personas that matter. For the first group of data scientists, there are open APIs and an integrated development environment (IDE) in which they can develop services directly against the unified data architecture. Analysts, who typically are less familiar with procedural programming approaches, can use the declarative paradigm of SQL to access data and call up functions within the unified data architecture. Some advanced algorithms are included now within Aster, as are a few big data visualizations such as sankey; on that topic, I think the best interactive sankey visualization for Aster is from Qlik Technologies, and was showcased at the company’s booth at the Teradata conference. The third persona and access point is the role of the knowledge worker, who accesses big data through BI and visualization tools. Ultimately, the Aster 6 platform brings an impressively integrated access approach to big data analytics; we have not yet seen its equal elsewhere in the market.
A key challenge that Teradata faces as it repositions itself from a best-in-class database provider for data warehousing to a big data and big data analytics provider is to articulate clearly how everything fits together to serve the business analyst. For instance, Teradata relies on its partner’s tools like visual discovery tools and analytical workflow tools such as Alteryx to tap into the power of its database, but it is hard to see how all of these tools use Aster 6. We saw the Aster 6 n-path analysis nicely displayed in an interactive sankey by QlikTech who I recently assessed, and an n-path node within the context of the Alteryx who I also analyzed advanced analytics workflow, but it is unclear how an analyst without specific SQL skills can do more than that. Furthermore, Teradata announced that its database integrates with the full library of advanced analytics algorithms through Fuzzy Logix, and through partnership with Revolution Analytics, R algorithms can run directly in the parallelized environment of Teradata, but again it is unclear how this plays with the Aster 6 approach. This is not to downplay the integration with Fuzzy Logix and Revolution Analytics because these are major announcements and they should not be underestimated especially for big data analytics. However, how these advancements align with the Aster approach and the usability of advanced analytics is still unclear. Our research shows that usability is becoming the most important buying criterion across categories of software and types of purchasers. In the case of next-generation business intelligence, usability is the number-one buying criterion for nearly two out of three (64%) organizations. Nevertheless, Aster 6 provides an agile, powerful and multifaceted data discovery platform that addresses the skills gap especially at the upper end of the analyst skills curve.
In an extension of this exploratory analytics position, Teradata also introduced cloud services. While we have seen vendors of BI and analytics as laggards in the cloud, it is increasingly difficult for them to ignore. Particular use cases are analytic sandboxes and exploratory analytics; in the cloud users can add or reduce resources as needed to address the analytic needs of the organization. Teradata introduced its cloud approach as TCO neutral which means that once you include all of the associated expense of running the service, it will be no more or less expensive than if it was to be run on premise. This runs counter to a lot of industry talk about the inexpensive nature of Amazon’s Redshift platform (based on the Paraccel MPP database that I wrote about). However, IT professionals who actually run databases are sophisticated enough to understand the cost drivers and know that a purely cost-based argument is a red herring. Network infrastructure costs, data governance, security and compliance all come into play since these issues are similar in the cloud as they are on-premises. TCO neutral is a reasonable position for Teradata since it shows that the company knows what it takes to deploy and run big data and analytics in the cloud. Although cloud players market themselves as less expensive, there still are plenty of expenses associated with it. The big differences are in the elasticity of the resources as well as the way the cost is distributed in the form of operational expenditures rather than capital expenditures. Buyers should consider all factors before making the datawarehouse cloud decision, but overall cloud strategy and use case are two critical criterions.
Its cloud computing direction is emblematic of the analytics market position that Teradata is aspiring to occupy. For years it has under-promised and over-delivered. This company doesn’t introduce products with a lot of hype and bugs and then ask the market to help fix them. Its reputation has earned it some of the biggest clients in the world and has built a high level of trust, especially within IT departments. As companies become frustrated with a lack of governance and security and a proliferation of data silos that today’s business-driven use of analytics spawns, I expect that the pendulum of power will swing back toward IT. It’s hard to predict when this may happen, but Teradata will be particularly well positioned when it does. Until then, on the business side it will continue to compete with systems integration consulting firms and other giants vying for the high level trusted advisor position in today’s enterprise. In this effort, Teradata has both industry and technical expertise and has established a center of excellence populated by some of the smartest minds in the big data world including Scott Nau, Tasso Argyros and Bill Franks. I recommend Bill Franks’ Taming the Big Data Tidal Wave as one of the most comprehensive and readable books on big data and analytics.
For large and midsize companies that are already Teradata customers, midsize companies with a cloud-first charter and any established organization rethinking its big data architecture, Teradata should be on the list of vendors to consider.




