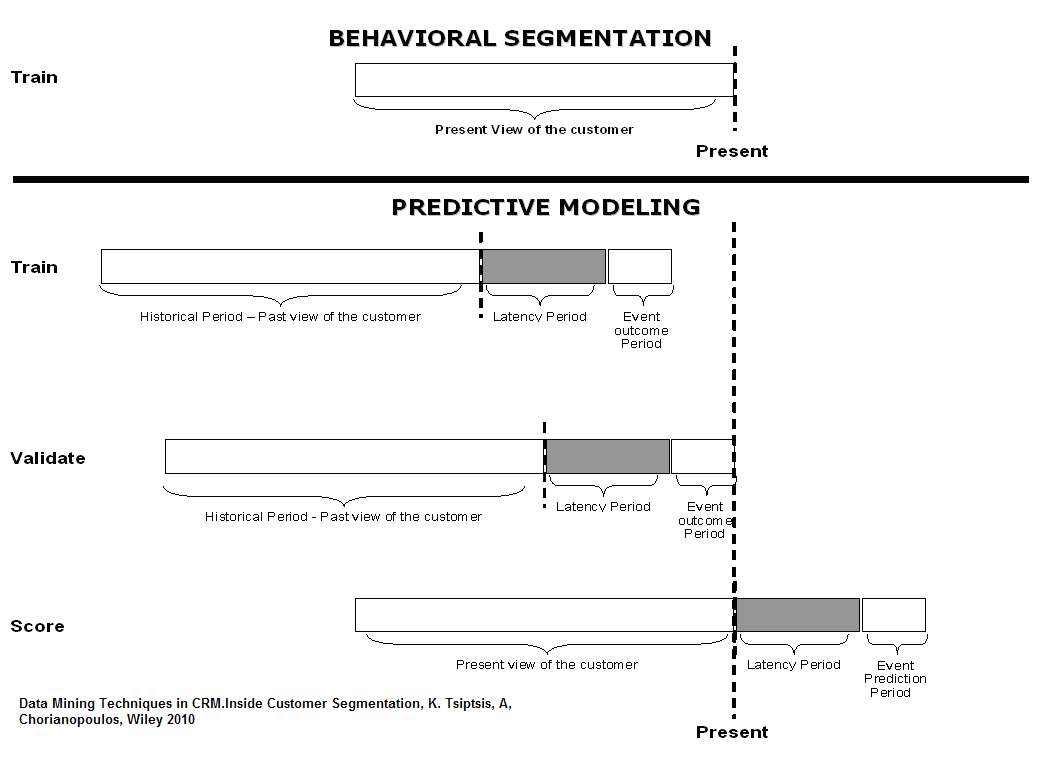
Classification models on the other hand, require the splitting of the modeling dataset in different time periods. To identify data patterns associated with the occurrence of an event, the model should analyze the customer profile before the event occurrence. Therefore, analysts should focus on a past moment and analyze the customer view before the purchase of an add-on product or before churning to a competitor.
Let’s consider for example a typical churn model. During the model training phase, the model dataset should be split to cover the following periods:
- Historical period: used for building the customer view in a past time period, before the occurrence of the event. It refers to the distant past and only predictors (input attributes) are used for building the customer view.
- Latency period: It is reserved for taking into account the time needed to collect all necessary information to score new cases, predict future churners and execute the relevant campaigns.
- Event outcome period: used for recording the event outcome, for example churned within this period or not. It follows the historical and the latency period and it is used for defining the output field of the supervised model.
The model is trained by associating input data patterns of the Historical period with specific event outcomes recorded in the Event outcome period.
Typically, in the validation phase, the model’s predictive performance is evaluated in a disjoint dataset which covers different time periods. In the deployment phase new cases are scored according to their present view, specifically, according to the input data patterns observed in the period right before the present. The event outcome is unknown and its future value is predicted.
![]()