
Similar to years past, data quality may yet again win the superlative award for the most discussed topic in the business intelligence industry. Unfortunately, it’s becoming about as boring to read as the usual “Top X Things NOT to do in BI Projects.” Yet, for the same reason those articles are written over and over again, we have to continuously discuss data quality because we’re still seeing the same mistakes from years ago.
Similar to years past, data quality may yet again win the superlative award for the most discussed topic in the business intelligence industry. Unfortunately, it’s becoming about as boring to read as the usual “Top X Things NOT to do in BI Projects.” Yet, for the same reason those articles are written over and over again, we have to continuously discuss data quality because we’re still seeing the same mistakes from years ago.
You might be wondering: “haven’t we corrected this by now?” Well, despite the emergence of tools to assuage our data quality concerns and provide assurances, the topic keeps itself blissfully relevant through our subtle inconsistencies, poor data collection methods and our overall lack of time and resources to squash the issues at their origin.
I still want to believe there’s an organization out there with pristine and perfect data, but after many business intelligence implementations across organizations of different sizes, industries and locations, I’ve learned that this is nothing more than wishful thinking. Data quality has been around for a long time (mainframes and address data, anyone?) and now with the explosion of data size (e.g. “big data”), we can be sure that data quality will remain a topic of discussion for years to come.
So, how exactly does business intelligence fit into this massive data quality picture? Funny (and sadly) enough, many organizations only find out about their data quality issues once they actually start using their business intelligence solution. The state of their data quality becomes apparent when the nice dashboards they expected don’t look as nice or useful and, in some scenarios, certain types of analysis aren’t available because the poor condition of the data quality renders them incomplete and/or impossible.
As they usually say—“garbage in, garbage out”—and if an organization wants to get the most out of its BI solution, data quality improvement has to be a priority regardless of the blatant reality that there will always be data quality issues to some extent.
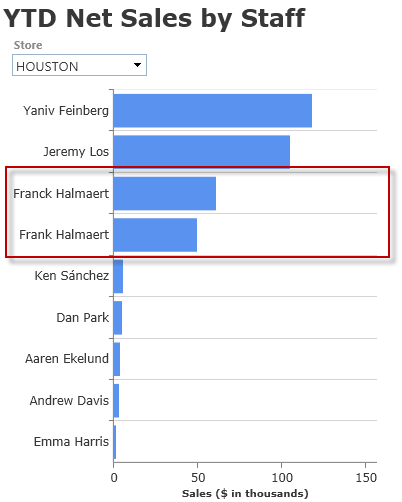
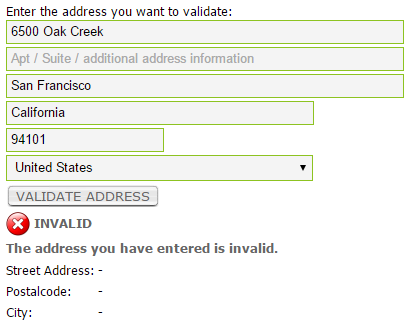
If this look familiar to you, then you’re feeling the effects of poor data in your BI
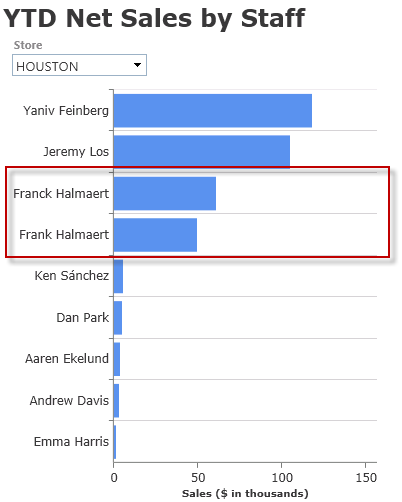
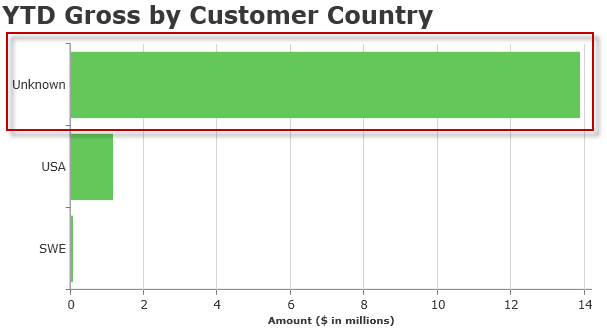
This is the reality and unless you have unlimited time with an unlimited budget, it’s foolish to expend great energy for 100% perfect data.
So, having said that, is there anything we can do to address all of this meaningfully and avoid the perils or bad data?
Surprisingly, yes – I believe there are a number of practical things organizations of any size should do. Here are some main themes that we should adopt when defining policies to address data quality issues and starting initiatives aimed at improving these:
1. Define accountability for data quality. As with most things in organizations, initiatives will only be internalized if there’s accountability. There’s usually a need to have a name behind something. This isn’t only to enjoy the benefits and recognition of things going right, but also to be responsible for fixing things when they go wrong. Just as financial figures are reported on across time and people are held to certain standards, simple data quality stats around business areas should be part of job descriptions as well as regular reporting at the operational, tactical and strategic levels.
For instance, how many invalid entries (e.g. blank customer attributes) did we have this month compared against the same month last year? These are questions that can be answered if the business intelligence solution reports basic stats and these are made part of the performance appraisal of key stakeholders. If you just want to do enact a single tactic to improve data quality, do this and you’ll be surprised how accountability will “magically” change things overnight.
2. Treat data quality with a risk-based approach. If we’ll never have 100% perfect data quality, the least we can do is identify which areas of our data definitely have to be right so that we focus all of our efforts effectively and pragmatically. An online retailer using business intelligence with invalid customer addresses will have serious issues operationally and these will inevitably flow through to the bottom line. Could we say the same thing about a company that insists on populating and maintaining a customer attribute even though no one is using it for reporting operationally or strategically? Eh, not entirely.
Let’s imagine an organization that knows its customer and vendor records are about 90% right. If they try to improve these two areas so that both get closer to 100%, they’re ignoring the fact that the improvement of these two might have a different impact on the performance of the company and that they’ll be doing A TON of work for very little marginal improvement.
A better approach is to understand the impact of a 1% improvement on the data quality of either and focus any efforts on the one that delivers the most benefits. An even better approach would be to understand whether a 1% improvement delivers a comparable benefit to a 1% deterioration, or another way to put it: if the deterioration of 1% of my customer records will make me lose more money than I’ll make by the 1% improvement of this. At that point, I can safely state that my customer records are a high risk area to my business and taking good care of them should be a priority. For example, creating metrics for employee appraisal to ensure the quality is maintained while making sure any capital invested in this area or any other initiatives are focused on managing and limiting this downside.
This is similar to the concept of wastage in manufacturing or the provisioning of bad debts in accounting but applying it to data quality. Please note that I’m not calling for the development of weird, complex and often useless mathematical models to analyze data quality. What I just described is understood intuitively by stakeholders that know their organizations, and business intelligence can help actualize this knowledge into real data quality initiatives with basic reporting of data quality statistics coupled with the development of basic what-if scenarios.
3. Improve data quality at the source. Business intelligence solutions are underpinned by “Extract, Transform, Load” (ETL) processes that extract data from the various source systems and load it into a data warehouse for reporting purposes. In my BI career, I’ve seen some pretty strange ETL processes that make attempts to fix data quality issues.
I genuinely believe the ETL should be as dumb as humanely possible. It should exist to integrate systems and, if necessary, make reporting easier by pre-aggregating figures or extending the existing model to cater for specific reporting needs.
Fixing data quality issues in the BI layer is a massive error in my opinion. It’s like treating chickenpox by applying makeup or pouring more kitty litter into a dirty litterbox. The source systems should already be providing the BI systems with good data and if there are any issues, the fix should be done in the source system, ideally around the data input layer.
The sooner an issue is highlighted, the more likely it will be fixed, and it’s better to aim for issues to not even be allowed to enter the source system in the first place. Your BI solution’s only task will be to expose the ones that managed to sneak in, and that’s really all it should be doing when it comes to processing data quality. Typical fixes in the source system could range from making sure an input field only accepts valid entries (e.g. zip code accepting only numbers), or validating the customer address entered against a list of valid addresses, to changing the source system database scheme through normalization to ensure data integrity is enforced.
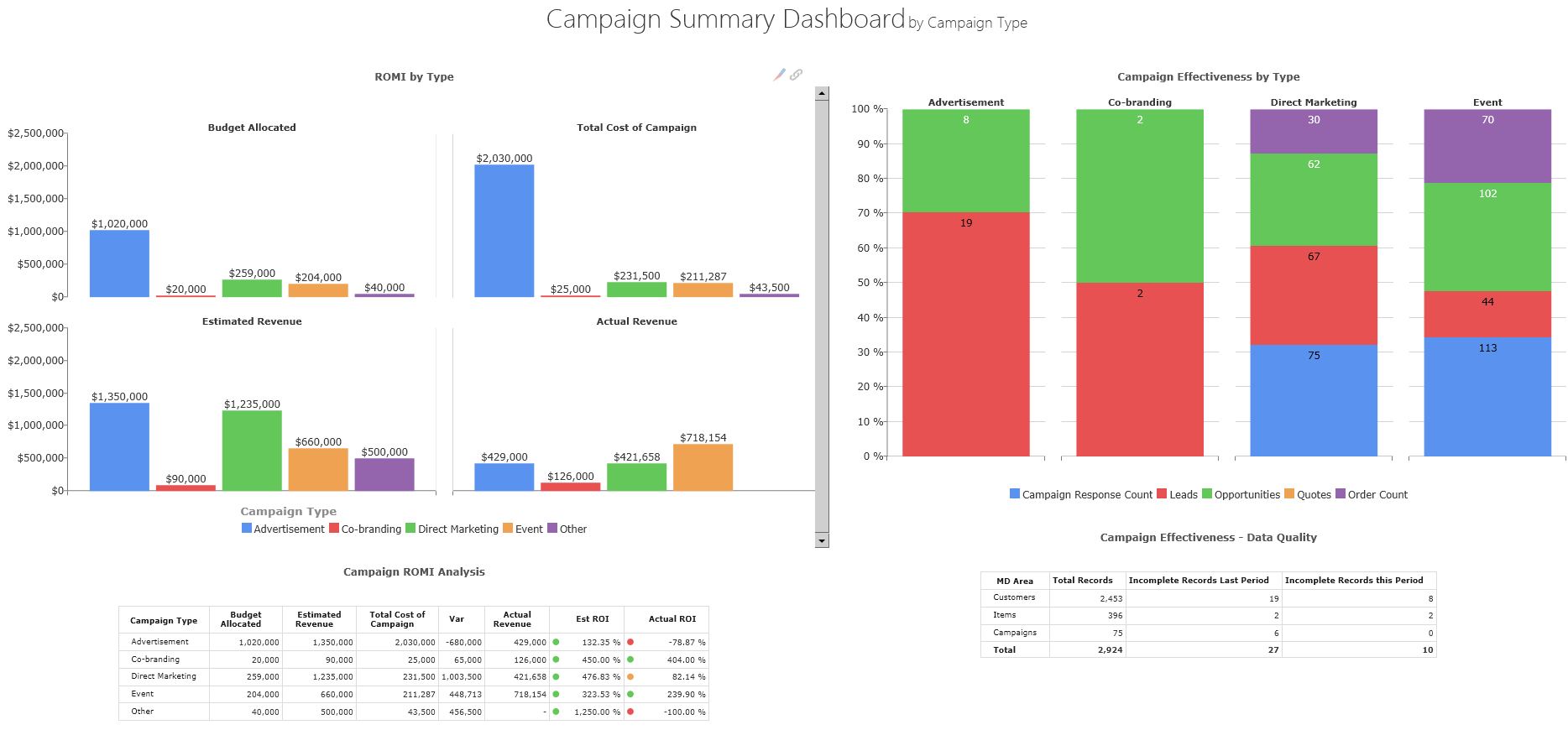
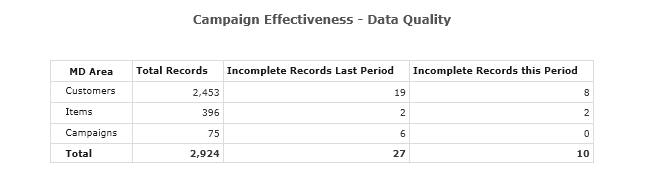
4. Report, identify, fix and repeat. Admittedly, it takes time to make data quality an indispensable part of an organization’s culture. The organization will find out what works and what doesn’t work; it’s a never-ending learning process. The business intelligence solution will include specific resources like dashboards that will highlight issues with the master data and transactions that are askew. The manager responsible here will identify these quickly through the BI platform and with this information they’ll be able to go back to the source system and fix the issues (which will presumably lead to projects improving the source system in question).
Overtime the number of issues will decrease and the same manager will identify data that isn’t extremely crucial for reporting or that needs to be added to the reporting of data quality. The BI solution will include these new metrics on a new iteration and the process starts again. It’s an iterative process that will not only deliver the business data they can rely on, but with time will also provide the organization with a competitive advantage.
Finally, it’s important to reiterate that data quality is something that should sit with the business and not with IT or the BI team. The business intelligence solution can play a vital role in helping the business identify what needs to be addressed so that the business can move quickly, just as it does with finance or operational figures. Putting someone’s name on each data area for data quality accountability purposes, understanding the risk and the impact of your data quality issues, creating projects on the source systems to improve data quality as you would when you want to add new functionality, and understanding all this is part of an iterative and never-ending process should guide you to address data quality effectively.





{kind=link}