A UK-based MSc student of Kingston Business School – Christos Gkemitzis- had an idea for his MSc project which immediately caught my attention : Use Text Analytics methods to annual reports given by Banks and extract metrics on how these Banks handle their Credit and Interest rate risk and then test several hypotheses (Do Banks of a higher risk profile disclose bigger amount of risk-related information compared to those having lower risk profile?). Also identify any correlations :
- between the size of the Bank a
A UK-based MSc student of Kingston Business School – Christos Gkemitzis- had an idea for his MSc project which immediately caught my attention : Use Text Analytics methods to annual reports given by Banks and extract metrics on how these Banks handle their Credit and Interest rate risk and then test several hypotheses (Do Banks of a higher risk profile disclose bigger amount of risk-related information compared to those having lower risk profile?). Also identify any correlations :- between the size of the Bank and volume of risk disclosures
- between the risk of the Bank’s profile and volume of risk disclosures
- between the profitability of the Bank and volume of risk disclosures
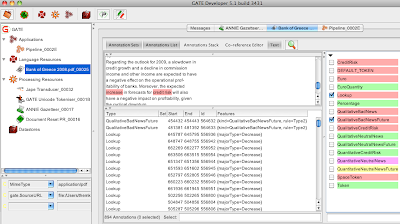
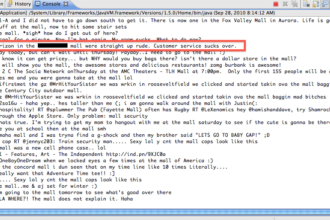
Essentially the problem is to -automatically- identify mentions of credit risk but in a specific way :1) Identify sentences mentioning risk refer to the present, past or future2) Identify positive, negative or neutral sentiment mentions about Credit Risk3) Identify qualitative versus quantitative information regarding the Bank’s Credit RiskFor example consider the following text which is part of an actual Bank report :“A substantial increase of credit risk and provisions is also expected, as from 2009 on, theeconomy will be entering a period of low growth.”The sentence above contains qualitative information (“substantial increase of credit risk and provisions”) and negative Sentiment referring to the future (“also expected” and “will be entering a period of…”).while the following sentence :“The Group’s ongoing efforts to manage efficiently credit risk led the level of loan losses to 3.3% in December 2008”contains quantitative information (“level of loan losses to 3.3%”) with a positive sentiment about Credit Risk handling in the past.After receiving some PDF samples of Bank reports from Christos, I began feeding these reports to the GATE Text Analysis toolkit in order to assess the feasibility of such analysis. After some tutorials through Skype, Christos -who had no prior knowledge of programming- started using the toolkit on his own in a very short amount of time. Here is a snapshot of GATE in action for the analysis : The snapshot shows how GATE correctly identified a part of text that communicates a negative sentiment for Credit Risk in a qualitative manner for the future (notice that “QualitativeBadNewsFuture” is checked).After running GATE in many documents, Christos had the necessary metrics (=how many mentions of different Risk types exist in a document) to test his hypotheses using a 2-tailed Wilcoxon test. To identify correlations, Spearman coefficient was also used.Since this is work which has not been submitted yet, it is not permitted to post the findings of this research. The post shows however another application of Text Analytics and the many sources of unstructured information that could be mined for knowledge.
The snapshot shows how GATE correctly identified a part of text that communicates a negative sentiment for Credit Risk in a qualitative manner for the future (notice that “QualitativeBadNewsFuture” is checked).After running GATE in many documents, Christos had the necessary metrics (=how many mentions of different Risk types exist in a document) to test his hypotheses using a 2-tailed Wilcoxon test. To identify correlations, Spearman coefficient was also used.Since this is work which has not been submitted yet, it is not permitted to post the findings of this research. The post shows however another application of Text Analytics and the many sources of unstructured information that could be mined for knowledge.