

Data analytics has become essential to helping businesses make strategic decisions. Software tools can help to spot patterns or discover insights into a wide range of processes. The data systems used to feed these strategies generally exist as vendor-specific enterprise data warehouse solutions. In these applications, information is loaded and structured so as to provide the most efficient results from very large collections of data.
Data Warehouses
Data warehouses are central repositories of data used to suggest new business insights. This data represents a comprehensive, cohesive view of the business. Typically, this is an historical dataset with the following characteristics:
Subject-Oriented: A data warehouse usually serves a specialized subject or business need, such as sales or manufacturing productivity.
Time-Variant: The data is historical, so that results can be analyzed in terms of specific time frames, such as by month or by quarter over the past two years. The enterprise data warehouse is usually fed with encapsulated data from a transactional system, where only recent data is essential. For instance, a transactional system may reflect only a customer’s most recent phone number, while a data warehouse will have all the previously used numbers.
Integrated: Data warehouses combine information from a number of different sources into a homogenous view. For instance, different stores may have different names for the same product, but they will still have the same SKU or part number.
Non-volatile: Information stored in the enterprise data warehouse does not change. To maintain the integrity of the historical data, it is read-only and never altered.
What kind of data is loaded into the data warehouse?
Operational data is near real-time, such as sales information captured at POS terminals from a chain of stores. Daily sales are captured by the system and fed into data files. These files are then subject to ETL (extract, transform, and load) software or scripts to organize, or “normalize” this data into fields that can be uploaded directly into data warehouse tables.
For instance, a large retail chain will want to capture what was sold, the sales person, the store, the time, payment method, special offers or coupons, and more. Another company may be more interested in collecting customer service activity for periodic performance analysis.
Most stored data is relational. This means information exists in the form of numeric ID fields that can be linked with a single table, for instance a list of product IDs linking to textual product names and descriptions for each distinct ID. This saves space in the enterprise data warehouse while providing more meaningful information in data reporting.
How a data warehouse differs from a traditional database
Databases support day-to-day operations by capturing information as it’s produced, whether electronically or manually. These are also called transactional or operational databases. They are primarily used for capturing information from the source. A database also allows for editing of information to more closely reflect real-world changes. They are optimized for data entry: coordinating small, frequent updates and additions. Data is organized into rows, or individual records.
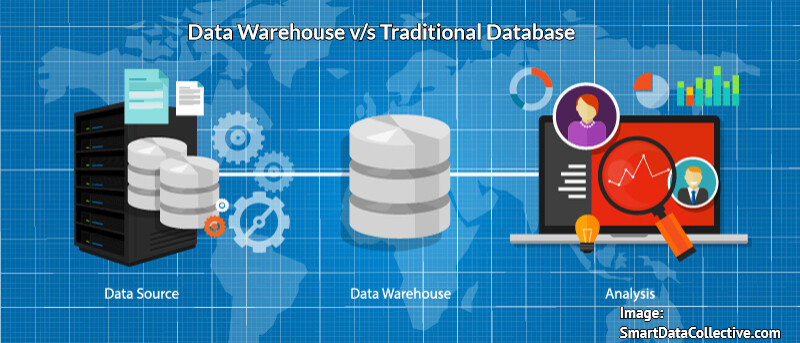
Although both systems can be used for reporting, a data warehouse is designed for aggregating large amounts of fixed information. The information in reports run from transactional data may be subject to change.
A data warehouse exists primarily for reporting and analysis of business operations over time in order to identify patterns. Information is typically extracted from one or multiple databases to become historical records in the data warehouse. A data warehouse will reflect all changes. Most enterprise data warehouse solutions require information to be stored in terms of columns, or dimensions, such as time or location, to retrieve a range of measures, such as dollars or quantities. This allows for drill-down through various levels of detail within the same reporting tool.
Data marts
Smaller companies, or even larger companies when approaching a particular data project, may segment data into smaller, more limited data sets known as “data marts”. This allows them to eliminate the operational overhead of excessive or irrelevant information. Data marts may be extracted from data warehouses as needed or exist separately.
New or smaller companies may not have the need to maintain a data warehouse. But in mid-range to large companies, there is usually daily use of both transactional databases and data warehouses. The important difference is that enterprise data warehouse solutions are read-only and optimized for analysis of a constantly growing amount of operational data to support business decisions.





{kind=link}