
Hadoop Summit is the biggest event on the West Coast centered on Hadoop, the open source technology for large-scale data processing. The conference organizers, Hortonworks, estimated that more than 2,400 people attended, which if true would be double-digit growth from last year. Growth on the supplier side was even larger, which indicates the opportunity this market represents. Held in Silicon Valley, the event attracts enterprise customers, industry innovators, thought leaders and venture capitalists. Many announcements were made – too many to cover here.
Hadoop Summit is the biggest event on the West Coast centered on Hadoop, the open source technology for large-scale data processing. The conference organizers, Hortonworks, estimated that more than 2,400 people attended, which if true would be double-digit growth from last year. Growth on the supplier side was even larger, which indicates the opportunity this market represents. Held in Silicon Valley, the event attracts enterprise customers, industry innovators, thought leaders and venture capitalists. Many announcements were made – too many to cover here. But I want to comment on a few important ones and explain what they mean to the emerging Hadoop ecosystem and the broader market.
Hortonworks is a company spun off by the architects of Yahoo’s Hadoop implementation. Flush with $50 million in new venture funding, the company announced the preview distribution of Apache Hadoop 2.0. This represents a fundamental shift away from the batch-only approach to processing big data of the previous generation. In particular, YARN (Yet Another Resource Manager; Yahoo roots are evident in this name) promises to solve the challenge of multiple workloads running on one cluster. YARN replaces the Hadoop Data Platform (HDP) job scheduler. In that system, a MapReduce job sees itself as the only tenant on HDFS, the Hadoop file system, and precludes any other workload. In YARN, MapReduce becomes a client of the resource manager, which can allocate resources according to differing workload needs. According to Bob Page, product manager at Hortonworks, and Shaun Connolly, VP of corporate strategy, this mixed workload capability opens the door to additional ISV plug-ins including advanced analytics and 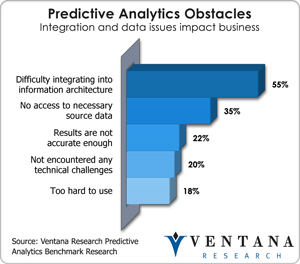 stream processing. Integrating workloads is an important step forward for advanced analytics; our benchmark research into predictive analytics shows that the biggest challenge to predictive analytics for more than half (55%) of companies is integrating it into the enterprise architecture. Furthermore, stream processing opens the door to a variety of uses in operational intelligence such as fraud prevention and network monitoring that have not been possible with Hadoop. The company plans general availability of Apache Hadoop 2.0 in the fall. Beyond, YARN, the new version of Hadoop will bring YARN, Hive on Tez for SQL query support, high availability, snapshots, disaster recovery and better rolling upgrade support. Hortonworks simultaneously announced a certification program that allows application providers to be certified on the new version. This next major release of Hadoop is a significant step to the enterprise readiness of Hadoop, and Hortonworks who depends on the open source releases for commercializing and licensing it to customers will now be able to better compete against some of its competitors who have built their own proprietary extensions to Hadoop as part of their offerings.
stream processing. Integrating workloads is an important step forward for advanced analytics; our benchmark research into predictive analytics shows that the biggest challenge to predictive analytics for more than half (55%) of companies is integrating it into the enterprise architecture. Furthermore, stream processing opens the door to a variety of uses in operational intelligence such as fraud prevention and network monitoring that have not been possible with Hadoop. The company plans general availability of Apache Hadoop 2.0 in the fall. Beyond, YARN, the new version of Hadoop will bring YARN, Hive on Tez for SQL query support, high availability, snapshots, disaster recovery and better rolling upgrade support. Hortonworks simultaneously announced a certification program that allows application providers to be certified on the new version. This next major release of Hadoop is a significant step to the enterprise readiness of Hadoop, and Hortonworks who depends on the open source releases for commercializing and licensing it to customers will now be able to better compete against some of its competitors who have built their own proprietary extensions to Hadoop as part of their offerings.
As noted, various vendors announced their own Hadoop advances at the summit. For one, Teradata continues to expand its Hadoop-based product portfolio and its Unified Data Architecture that I covered recently. The company introduced the Teradata Appliance for Hadoop as well as support for Hadoop utilizing Dell’s commodity hardware. While another Hadoop appliance in the market may not be big news, the commitment of Teradata to the Hadoop community is important. Its professional services work in close partnership with Hortonworks, and now they will offer full scoping and integration services along with the current support services. This enables Teradata to maintain its trusted advisor role within accounts while Hortonworks can take advantage of a robust services and account management structure to help create new business.

Quentin Clark, Microsoft’s VP for SQL Server, gave a keynote address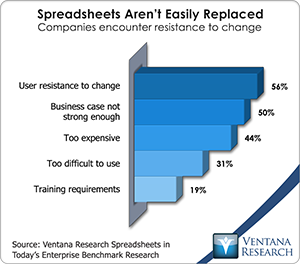 acknowledging the sea change that is occurring as a result of Hadoop. But he emphasized Microsoft’s entrenched position with Excel and SQL Server and the ability to use them alongside Hortonworks for big data. It’s a sound if unfortunate argument that spreadsheets are not going away soon; in our latest benchmark research into spreadsheets 56 percent of participants said that user resistance is the biggest obstacle to change. At the same time, Microsoft has challenges in big data such as a truly useable interface beyond Microsoft Excel, which I recently discussed. At Hadoop Summit, Microsoft reiterated announcements already made in May and were covered by my colleague. They included Hortonworks Data Platform for Windows, in which Hadoop becomes a key priority operating system alongside of SQLServer, and HDsight running on Azure, Microsoft’s cloud platform. The relationship will help Hortonworks overcome objections about the security and manageability of its platform, while Microsoft should benefit from increased sales of its System Center, Active Directory and Windows software. Microsoft also announced the HDP Management Packs for Systems Center that makes Hadoop easier to manage on Windows or Linux and utilizes Ambari API for integration. Perhaps the most interesting demonstration from Microsoft was the preview of Data Explorer. This application provides text-based search across multiple data sources, after which the system can import the various data sources automatically, independent of their type or location. Along with companies like Lucidworks (which my colleague Mark Smith recently discussed, and Splunk, Microsoft is advancing in the important area of information discovery, one of the four types of big data discovery Mark follows.
acknowledging the sea change that is occurring as a result of Hadoop. But he emphasized Microsoft’s entrenched position with Excel and SQL Server and the ability to use them alongside Hortonworks for big data. It’s a sound if unfortunate argument that spreadsheets are not going away soon; in our latest benchmark research into spreadsheets 56 percent of participants said that user resistance is the biggest obstacle to change. At the same time, Microsoft has challenges in big data such as a truly useable interface beyond Microsoft Excel, which I recently discussed. At Hadoop Summit, Microsoft reiterated announcements already made in May and were covered by my colleague. They included Hortonworks Data Platform for Windows, in which Hadoop becomes a key priority operating system alongside of SQLServer, and HDsight running on Azure, Microsoft’s cloud platform. The relationship will help Hortonworks overcome objections about the security and manageability of its platform, while Microsoft should benefit from increased sales of its System Center, Active Directory and Windows software. Microsoft also announced the HDP Management Packs for Systems Center that makes Hadoop easier to manage on Windows or Linux and utilizes Ambari API for integration. Perhaps the most interesting demonstration from Microsoft was the preview of Data Explorer. This application provides text-based search across multiple data sources, after which the system can import the various data sources automatically, independent of their type or location. Along with companies like Lucidworks (which my colleague Mark Smith recently discussed, and Splunk, Microsoft is advancing in the important area of information discovery, one of the four types of big data discovery Mark follows.
Datameer made the important announcement of version 3.0 of its namesake flagship product with a celebrity twist. Olympic athlete Sky Christopherson presented a keynote telling how the U.S. women’s cycling team, a heavy underdog, used Datameer to help it earn a silver medal in London. Following that, Stephen Groschupf, CEO of Datameer and one of the original contributors to Nutch (Hadoop’s predecessor), discussed advances in 3.0, which include a variety of advanced analytic techniques such as clustering, decision trees, recommendations and column dependencies. The ability to do these types of advanced analytics and visualize the data natively on Hadoop is not currently available in the market. My coverage of Datameer from last year can be found here.
Splunk announced Hunk, a tool that integrates exploration and visualization in Hadoop and will enable easier access for ‘splunking’ Hadoop clusters. In this tool, Splunk introduces a virtual indexing technology in which indexing occurs in an ad-hoc fashion as it is fed into a columnar data store. This enables analysts to test hypotheses through a “slice and dice” approach once the initial search discovery phase is completed. Sanjay Meta, VP of marketing for Splunk, explained to me how such a tool enables faster time-to-value for Hadoop. Currently there are multiple requests for data resting in Hadoop, but it takes a data scientist to access them. By applying Splunk’s tools to the Hadoop world, the data scientists can move on to more valuable tasks while users trained in Splunk can register and address such requests. Hunk is still somewhat technical in nature and requires specific Splunk training, but the demonstration showed a no-code approach that through the user-friendly Splunk interface returns robust descriptive data in visual form, which can then be worked with in an iterative fashion. My most recent analysis of Splunk can be found here.
Pentaho also made several announcements. The biggest in terms of market impact is that it has become the sole ETL provider for Rackspace’s Hadoop-as-a-service initiative, which aims to deliver a full big data platform in the cloud. Pentaho also announced the Pentaho Labs initiative which will be the R&D arm for the Pentaho open source community. This move should lift both the enterprise and the community, especially in the context of Pentaho’s recent acquisition of Webdetails, a Portuguese analytics and visualization company active in Pentaho’s open source community. The company also announced Adaptive Big Data Layer, which provides a series of plug-ins across the Hadoop ecosystem including all of the major distributions. And a new partnership with Splunk enables read/write access to the Splunk data fabric. Pentaho also is providing tighter integration with MongoDB (including aggregation frameworks) and the Cassandra DBMS. Terilyn Palanca, director of Pentaho’s big data product marketing, and Rebecca Shomair, corporate communications director, made the point that companies need to hedge their bets within the increasingly divergent Hadoop ecosystem and that Pentaho can help them reduce risk in this regard. Mark Smith’s most recent analysis of Pentaho can be found here.
In general what struck me most about this exciting week in the world of Hadoop are the divergent philosophies and incentives at work in the market. The distributions of Map R, Hortonworks, Cloudera and Pivotal (Greenplum) continue to compete for dominance with varying degrees of proprietary and open source approaches. Teradata is also becoming a subscription reseller of Hortonworks HDP to provide even more options to its customers. Datameer and Platfora are taking pure-play integrated approaches, and Teradata, Microsoft and Pentaho are looking at ways to marry the old with the new by guarding current investments and adding new hadoop based capabilities. Another thing that struck me was that no Business intelligence vendors had a presence outside of visual discovery provider, Tableau. This is curious given that many vendors this week talked about responding to the demands of business users for easier access to Hadoop data. This is something our research shows to be a buying trend in today’s environment: Usability is the most important buying criterion in almost two out of three (64%) organizations. Use cases say a lot about usability and people talking on stage and off about their Hadoop experiences increased dramatically this year. I recently wrote about how much has changed in the use of big data in one year, and the discussions at Hadoop Summit confirmed my thoughts. Hortonworks and it ecosystem of partners are now able to further gain opportunity to meet a new generation of big data and information optimization needs. At the same time, we are still in the early stages of turning this technology to business use that requires a focus on use cases and gaining benefits on a continuous basis. Disruptive innovations often take decades to be fully embraced by organizations and society at large. Keep in mind that it was only in December 2004 that Google Labs published its groundbreaking paper on MapReduce.



