With businesses becoming increasingly sensitive to customer opinion of their brand, monitoring consumer feedback is becoming ever more important.
With businesses becoming increasingly sensitive to customer opinion of their brand, monitoring consumer feedback is becoming ever more important. Additionally, the recognition of social media as an important and valid source of customer opinion has brought about a need for new systems and a new approach.
Traditional approaches of reactive response to any press coverage by a PR department, or conducting infrequent customer surveys whether online or by phone are all part of extremely slow-cycle feedback loops, no longer adequate to capture the ever-changing shifts in public sentiment.
They represent a huge hindrance to any business looking to improve brand relations, delay in feedback can cost real money. Inevitably, the manual sections of traditional approaches create huge delays in information reaching its users. These days, we need constant feedback and we need low-latency – the information needs to be almost real-time. Wait a few moments too long, and suddenly the intelligence you captured could be stale and useless.
A social media listening post
Witness the rise of the “social media listening post”: a new breed of system designed to plug directly in to social networks, constantly watching for brand feedback automatically around the clock. Some forward-thinking companies have already built such systems. How does yours keep track right now? If your competitors have it and you don’t, does that give them a competitive advantage over you?
I’d argue for the need for most big brands to have such a system these days. Gone are the days when businesses could wait months for surveys or focus groups to trickle back with a sampled response from a small select group. In that time, your brand could have been suffering ongoing damage, and by the time you find out, valuable customers have been lost. Intelligence is readily available these days on an near-instantaneous basis, can you afford not to use it?
Some emerging “Big Data” platforms offer the perfect tool for monitoring public sentiment toward a company or brand, even in the face of the rapid explosion in data volumes from social media, which could easily overwhelm traditional BI analytics tools. By implementing a social media “listening post” on cutting-edge Big Data technology, organisations now have the opportunity to unlock a new dimension in customer feedback and insight into public sentiment toward their brands.
Primarily, we must design the platform for low-latency continuous operation to allow complete closure of the feedback loop – that is to say, events (news, ad campaigns etc) can be monitored for near-real time positive/negative/neutral response by the public – thus bringing rapid response, corrections in strategy, into the realm of possibility. Maybe you could just pull that new ad campaign early if something disastrous and unexpected happened to public reaction to the material? It’s also about understanding trends and topics of interest to a brand audience, and who are the influencers. Social media platforms like Twitter offer a rich granular model for exploring this complex web of social influence.
The three main challenges inherent in implementing a social media listening post are:
- Data volume
- Complexity of data integration – e.g. unstructured, semi-structured, evolving schema etc
- Complexity of analysis – e.g. determining sentiment: is it really a positive or negative statement with respect to the brand?
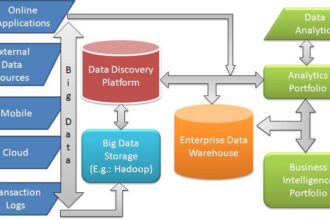
To gain a complete picture of public opinion towards your brand or organisation through social media, many millions of web sites and data services must be consumed, continuously around the clock. They need to be analysed in complex ways, far beyond traditional data warehouse query functionality. Even just a sentiment analysis capability on its’ own poses a considerable challenge, and as a science is still an emerging discipline, but even more advanced techniques in Machine Learning may prove necessary to correctly interpret all signals from the data. Data format will vary greatly among social media sources, ranging from regular ‘structured’ data through semi-and unstructured forms, to complex poly-structured data with many dimensions. This structural complexity poses extreme difficulty for traditional data warehouses and up-front ETL (Extract-Transform-Load) approaches, and demands a far more flexible data consumption platform.
So how do we architect a system like this? Generally speaking, at its core you will need some kind of distributed data capture and analysis platform. Big Data platforms were designed to address problems where you have Volume, Variety, or Velocity of data – and most often, all three. In this particular use-case, we need to look towards the cutting-edge of the technology, and look for a platform which supports near-real time, streaming data capture and analysis, with the capability to implement Machine Learning algorithms for the analytics/sentiment analysis component.
For the back-end, a high-throughput data capture/store/query capability is required, suitable for continuous streaming operation, probably with redundancy/high-availability, and a non-rigid schema layer capable of evolving over time as the data sources evolve. So-called “No-SQL” database systems (which in fact stands for “Not Only SQL” rather than NO SQL) such as Cassandra, HBase or MongoDB offer excellent properties for high-volume streaming operation, and would be well suited to the challenge, or there are also commercial derviatives of some of these platforms on the market, such as the excellent Acunu Data Platform which commercialises Cassandra.
Additionally a facility for complex analytics, most likely via parallel, shared-nothing computation (due to the extreme data volumes) will be required to derive any useful insight from the data you capture. For this component, paradigms like MapReduce are a natural choice, offering the benefits of linear scalability and unlimited flexibility in implementing custom algorithms, and libraries of Machine Learning such as the great Apache Mahout project have grown up around providing a toolbox of analytics on top of the MapReduce programming model. Hadoop is an obvious choice when it comes to exploiting the MapReduce model, but since the objective here is to achieve near-real time streaming capability, it may not always be the best choice. Cassandra and HBase (which in fact runs on Hadoop) can be a good choice since they offer the low-latency characteristics, coupled with MapReduce analytic capabilities.
Finally, some form of front-end visualization/analysis layer will be necessary to graph and present results in a usable visual form. There are some new open-source BI Analytics tools around which might do the job, or a variety of commercial offerings in this area. The exact package to be selected for this component is strongly dependent on the desired insight and form of visualization and so is probably beyond the scope of this article, but of course requirements are clearly that it needs to interface with whatever back-end storage layer you choose.
Given the cutting-edge nature of many of the systems required, a solid operational team is really essential to maintain and tune the system for continuous operation. Many of these products have complex tuning requirements demanding specialist skill with dedicated headcount. Some of the commercial open-source offerings have support packages that can help mitigate this requirement, but either way, the need for operational resource must never be ignored if the project is to be a success.
The technologies highlighted here are evolving rapidly, with variants or entirely new products appearing frequently, as such it would not be unreasonable to expect significant advancement in this field within the 6-12 month timeframe. This will likely translate into advancement on two fronts: increased and functional capability of the leading distributed data platforms in areas such as query interface and indexing capability, and reduced operational complexity and maintenance requirements.
Big Data Partnership help organisations unlock the value in their big data. We would be delighted to discuss further the use case outlined above should you wish to explore adapting these concepts to your own business.