


The recent data lake debate with my colleague, Anne Buff, may be over, but the discussion in many organizations is just getting started. What we learned during the debate—and you may be discovering in your own organization—is that it forces the larger discussion of managing growing volumes of data in a big data world. With the onslaught of big data technologies in recent years, organizations are having to look once again at the underlying technologies supporting their data collection, processing, storage, and analysis activities. And right now, the Hadoop-based data lake happens to be a very popular option.
About the data lake. Before we jump into the “to data lake or not to data lake” discussion, let’s define what a data lake is. Here’s the definition we used during our debate:

A data lake is a storage repository that holds a vast amount of raw data in its native format, including structured, semi-structured, and unstructured data. The data structure and requirements are not defined until the data is needed.
James Dixon, who identifies himself as the Chief Geek at Pentaho, coined the term data lake and describes it this way:
“If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lakeis a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
SWOTing the data lake. To help keep the discussion balanced (since I realize I come to the table with my own biases), I’m using the infamous SWOT diagram to identify some of the key factors associated with a data lake. [Some of you may recognize it from a recent post.] This quick snapshot is designed to help you get the data lake conversation started within your own organization:
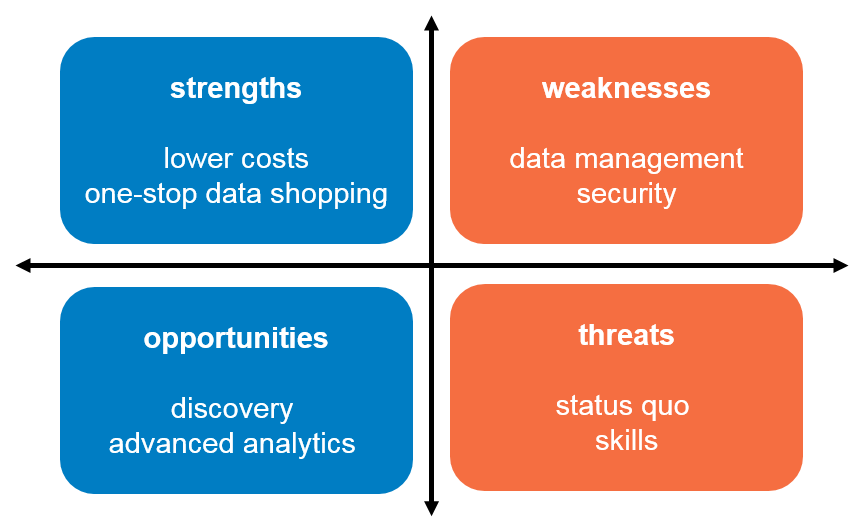
- Strengths
- Lower costs. A Hadoop-based data lake is largely dependent on open source software and is designed to run on low-cost commodity hardware. So from a software and hardware standpoint, there’s a huge cost savings that cannot be ignored.
- One-stop data shopping. Hadoop is no respecter of data. It will store and process it all – structured, semi-structured, and unstructured—at a fraction of the cost and time of your existing, traditional systems. There’s much to be gained from having all (or much of) your data in one place – mixing and matching data sets like never before.
- Weaknesses
- Data management. We can get hung up talking about the volume, variety, and velocity of (big) data, but equally important to this discussion is being able to govern and manage all of it, regardless of the underlying technologies. For a Hadoop-based data lake, both open source projects and vendor products continue to mature/be developed to support this increasing demand. We’re moving in the right direction—rapidly—but we’re not quite there yet.
- Security. Hadoop-based security has been a long-time issue, but there’s significant effort and progress being made by the open source community and vendors to support an organization’s security and privacy requirements. While it’s easy to finger wag at this particular “weakness,” it’s important to recognize that the weekly (and almost daily) reports we hear about this-&-that data breach are primarily attacks on existing traditional systems, not these newer big data systems.
- Opportunities
- Discovery. This feature allows users to discover the “unknown unknowns.” Unlike existing data warehouses where users are limited with both the questions and answers they can ask and get answers for, with a Hadoop-based data lake, the sky’s the limit. A user can go to the data lake with the same set of questions she had for the data warehouse and get the same, or even better, answers. But she can also discover previously-unknown questions, thus driving her to more answers, and ideally, better insights.
- Advanced analytics. A lot of software apps include descriptive analytics, showing a user pretty visuals about what’s happened. We’ve had this capability for decades. With big data, however, organizations need advanced analytics—such as prescriptive, predictive, and diagnostic—to really get ahead of the game (and one could even argue to stay in the game). A Hadoop-based data lake provides that opportunity.
- Threats
- Status quo. This is not a new threat, especially for software vendors, but it’s a very real threat. The cost and time required to migrate towards these newer big data technologies is not insignificant. This is not a case of hot-swapping technologies while no one is looking. It will also impact the people, processes, and the culture in your organization—if done right.
- Skills. There is no question that there is a skills shortage for these big data technologies. Even though this shortage can be viewed as a threat to Hadoop adoption, it shouldn’t be seen as a negative. These big data technologies are new, they’re evolving, and there’s a lot of experimentation going on to figure out what’s needed, what’s not, what should stick, what shouldn’t, etc. Thus, it should be no surprise that as our technologies evolve, so will the skills required. We have an opportunity to take what we have and know to a new level and help prepare the next generation to excel in our data-saturated society.
The bottom line. There are well-known weaknesses and threats associated with a data lake, some of which I have highlighted here. We cannot ignore these. But there are also significant strengths and opportunities to explore. If an organization wants to take full advantage of all its data, the data lake can provide the road for you to get there. Just don’t forget to buckle up!








{kind=link}