





Did you know that most Americans (87%) can be uniquely identified from just three pieces of personal data: a birth date, five-digit zip code and gender? Sort of disconcerting, right?
Did you know that most Americans (87%) can be uniquely identified from just three pieces of personal data: a birth date, five-digit zip code and gender? Sort of disconcerting, right?
This oft-quoted statistic was initially reported over 15 years ago in a 2000 Carnegie Mellon University paper1 on Personally Identifiable Information (PII). Even though the dates have changed and data volumes have grown exponentially since this report, the challenge is still the same: protecting one’s personal identity in the name of privacy.
PII is at the heart of the anonymized data debate. In my last post, I debunked a belief about anonymized data, namely: Anonymized data keeps my personal identity private. The more accurate statement I proposed was: Individuals may be re-identified from anonymized data. Let’s explore this one a bit further.
About PII and anonymized data. What does it mean to anonymize (or de-identify) data? In simple terms, it means removing any information from a data set that could personally identify a specific individual; for example, the person’s name, a credit card number, a social security number, home address, etc. Companies that sell consumer data, such as data brokers, typically only sell anonymized, and often aggregated, data. So if PII is stripped from these data sets (as depicted in the figure below), what’s the big deal?


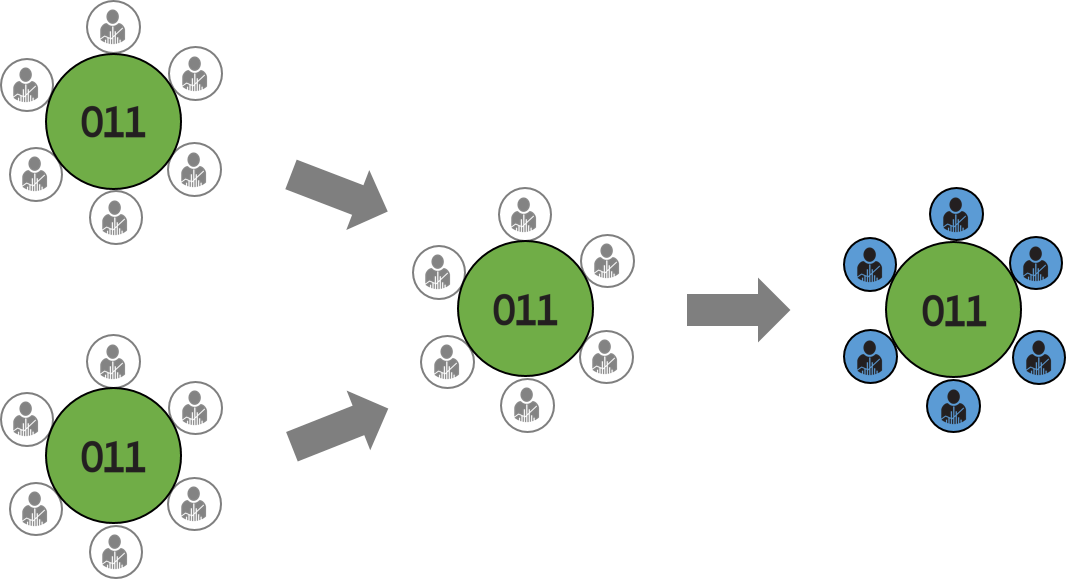
If we’re talking about a single data set (like the example above), then it’s probably not that big of a deal. Where it gets interesting, though, is when multiple data sets are combined. The figure below is a simplistic view of what a data aggregator (or broker) does with data sets:
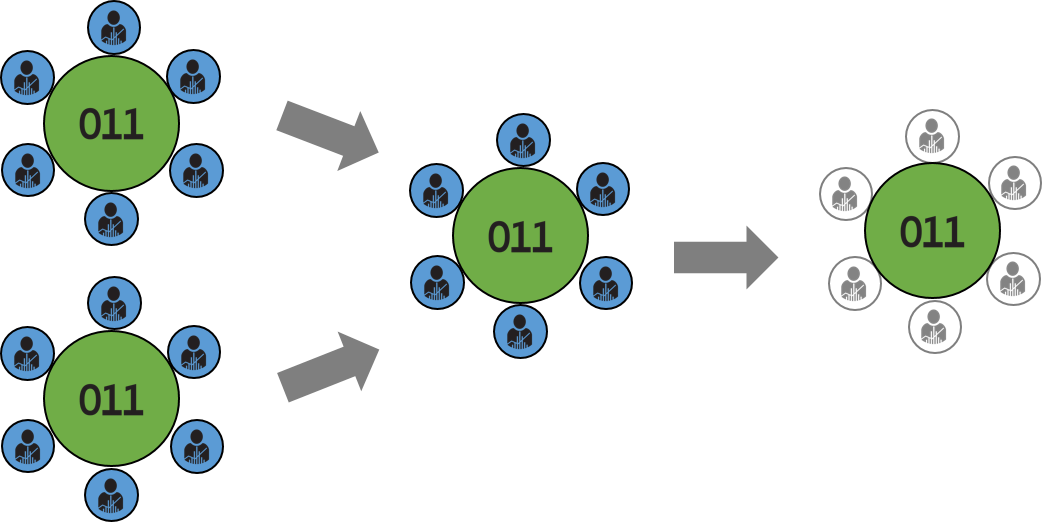

These two data sets could be totally harmless, but when brought together and analyzed over time, they could introduce new privacy concerns. Microsoft’s Cynthia Dwork illustrates it this way: “What’s the harm in learning that I buy bread? There is no harm in learning that, but if you notice that, over time, I’m no longer buying bread, you may conclude that maybe I have diabetes … What’s going on here is a failure of privacy mechanisms; they’re not composing effectively.”
Why this matters. Let’s go back to my earlier question: If my personally identifiable information (PII) is being stripped out and aggregated before it’s sold or gets passed on, what’s the big deal?
The big deal is this: With today’s big data technologies, it’s becoming easier to re-identify individuals from this anonymized data. Programming techniques continue to be developed to pull these anonymized pieces back together from one or more data sets. So if a company says it anonymizes your data before passing it onto others, be aware that your identity could still be revealed through advanced re-identification techniques.

{kind=link}
There is actually a heated debate going on about this. One camp stands firmly behind the techniques and algorithms being used to anonymize data; and they’re rather confident that individuals can’t be re-identified because the technology just isn’t there. The other camp doesn’t buy it, and says that re-identification algorithms are, in fact, working and only getting better. They also point out how some of the anonymization techniques currently being used simply don’t work.
I tend to agree with the latter camp. Even if it’s not happening now, it’s just a matter of time before the technologies and algorithms rise to a level of sophistication that not only re-identifies individuals faster, but does so faster and cheaper.
One final thought. Re-identification algorithms aren’t good or bad; it just depends on how they’re used. So when a well-meaning company or data broker tells you that your personal information is protected and is not shared with or sold to others, this is not an invitation to let your guard down. You know how it works now—so take heed and be vigilant.
1 Updated reference. Originally attributed to a 2001 AT&T research paper.