

The latest innovation in the proxy service market makes every data gathering operation quicker and easier than ever before. Since the market for big data is expected to reach $243 billion by 2027, savvy business owners will need to find ways to invest in big data. Artificial intelligence is rapidly changing the process for collecting big data, especially via online media.
The Growth of AI in Web Data Collection
An entire generation of software engineers, data scientists, and even technical executives working in web data reliant industries are familiar with the pains of web data gathering, also known as web scraping. In brief, ineffective information retrieval, collection of incomplete or low-quality data, and complex data treatment operations are causing the most difficulties.
In this climate, the latest innovation in the industry – Next-Gen residential proxies are quickly gaining popularity among web-scraping professionals. The new web data gathering tool, powered by AI and machine learning (ML) algorithms, promises a staggering 100% success rate for scraping sessions, among many other advantages.
Revolutionizing the approach to web data gathering
“Companies should focus more on the intelligence they retrieve instead of the data collection process,” – says Aleksandras Sulzenko, Product Owner of Next-Gen Residential proxies and ex-account manager at the Oxylabs Proxy Service.

Aleksandras’ valuable experience in the web-scraping business has given him a unique insight into the problems and solutions which follow data-driven companies every day. He continues:
“Perfecting data gathering methods is essential, especially now that the market value of big data has reached $200 billion. However, even the most technically advanced companies suffer from unstable web data gathering processes. Often they are plagued by the same factors, such as continuously blocked proxies, complex scraping infrastructure upkeep, poor data quality, and constant need to upgrade parsers, to name a few.
These hurdles can negatively influence other business operations, and missed business intelligence can lead to lost business opportunities or even strategic miscalculations.
That is why it was so important to revolutionize the way we approach web scraping. The Oxylabs team has established an advisory board made of the sharpest minds in the AI, ML, and data science fields in order to achieve this goal. All current board members have impressive backgrounds in global tech companies such as Google and Microsoft, and come from notable academic institutions, including MIT, Harvard, and UCL.”
Web-scraping roadblocks
According to Aleksandras, one of the major factors preoccupying web data gathering professionals are interrupted web scraping sessions.
“Probably every company that gathers and analyzes online data has, at some point, ran into roadblocks. This hindrance occurs because websites employ bot protection solutions, which are trained to recognize and limit online activity that appears not to be carried out by a human,” explains Alexandras.
For years now, the classic solution for data-reliant businesses were proxies and sometimes relied on scraping tools with the programming language R. In particular, residential proxies were the preferred choice for web-scraping professionals worldwide. However, anti-scraping solutions are evolving too, making these traditional data gathering methods outdated and more burdensome than before.
“Now, many popular online intelligence sources choose to implement sophisticated defense systems, such as extensive fingerprinting or CAPTCHAs, so we aimed to develop a solution, which would, by design, pass all blocks.”
Shortcut to block-free scraping
The first revolutionary feature in Next-Gen Residential Proxies is the AI-powered dynamic fingerprinting. It allows automated scraping operations to remain undetectable by convincingly imitating real-life human browsing patterns and providing user-related information.
At the same time, these properties enable data collectors to avoid CAPTCHAs and IP bans, even when gathering data from particularly challenging sites.
Barriers to high-quality data
It is evident that all collected data must meet certain quality criteria so that it could be meaningfully used in a business setting. However, due to many factors, not every scraping session can deliver satisfactory results. Therefore, data quality assurance is essential. The web-scraping community is painfully aware of how costly and time-consuming it can be. Aleksandras adds:
“In order to ensure data quality, data collectors must monitor the results of every scraping session. They need to dedicate countless hours and resources to make all the necessary quality checks, and also restart or tweak their web scraping approaches every time poor results come up.
On top of that, many target websites require JavaScript execution to deliver good-to-use information. This step alone requires expensive browser infrastructure upkeep.”
Shortcut to quality data
When asked about the best solution to overcome the data quality assurance obstacles, Aleksandras indicated that data collectors would benefit the most from the tool which could carry out all the manual steps without any human intervention.
“With the help of the latest technologies available today, we managed to automate certain aspects relating to data quality assurance. Next-Gen Residential Proxies are intelligent enough to recognize low quality or unusable data and restart the collection process as many times as needed until the satisfactory results are delivered.”
Also, when it comes to JavaScript rendering, Aleksandras pointed out that Next-Gen Residential Proxies are capable of executing this operation on the data collectors’ behalf, giving an option to forgo the demanding maintenance of required infrastructure.
Taking proxy solutions further with adaptive parsing
“Traditionally, when the parsing stage begins, proxy service ends, but we wanted to revolutionize that too,” – affirms Aleksandras. “We saw a potential to expand the limits holding back the industry professionals by creating a solution capable of including a broader scale of data collection elements.”
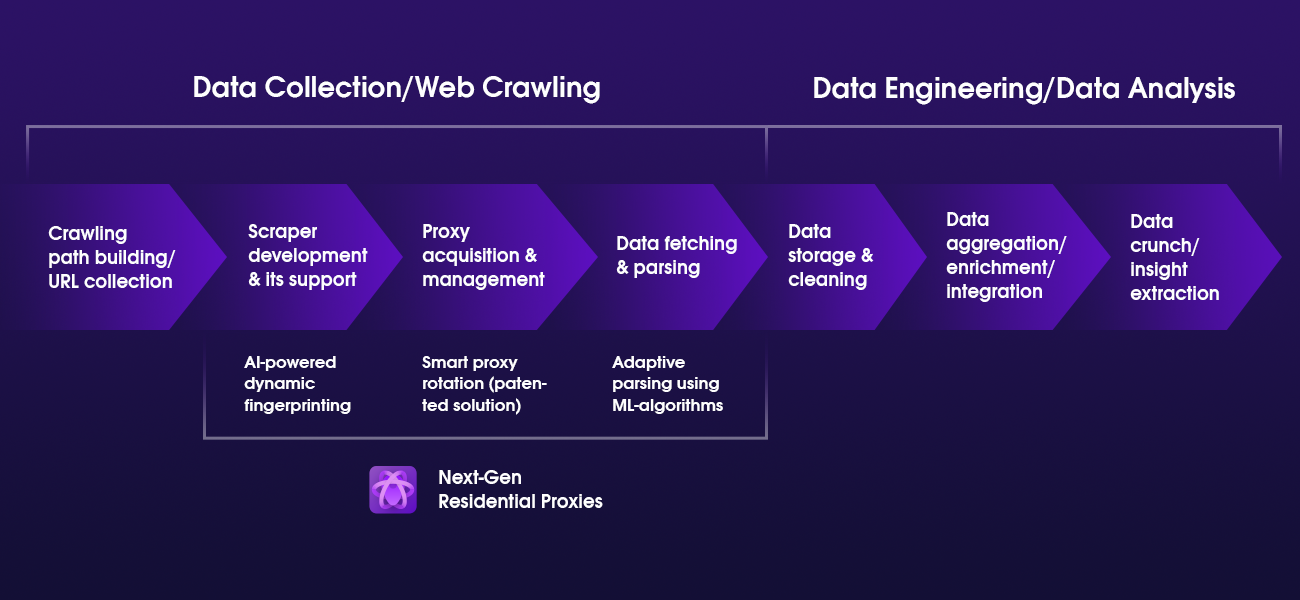
Currently in beta, the adaptive parsing feature, powered by machine learning algorithms, is the latest addition to the Next-Gen Residential Proxies. It can parse various e-commerce website pages adapting to quickly changing layouts. According to Aleksandras, it means that web scraping reliant companies will no longer need to develop their own custom parsers, which will allow them to dedicate more time and resources to other areas of their business.
AI is Changing the Future of Web Data Collection for the Better
Next-Gen Residential Proxies are quickly becoming the industry disruptor, eradicating previously unavoidable problems and obstacles. In fact, this solution makes data collectors worldwide to face a new reality, where interrupted scraping sessions are only a bad memory, data quality assurance is automatic, and data treatment processes are optional.
Moreover, constant updates and improvements to the solution don’t seem to slow down, promising even more features to ease web-scraping processes.
“To this day, Next-Gen Residential Proxies remain the most innovative and foolproof web data gathering solution the market has to offer. We will work hard to ensure that it continues to push the boundaries, reaffirming our commitment to continuous innovation here at Oxylabs,” concludes Aleksandras.








{kind=link}